Merci beaucoup Anthony d'avoir pris le temps de coécrire cet article avec moi.
Introduction
Cypress est un framework JavaScript de “end to end testing”, il permet de tester le rendu et les actions utilisateurs de l'application à l'aide de scénarios. Ici, nous allons l’utiliser pour développer l’interface graphique de notre application à partir des tests, plus précisément des tests de composants. On va donc faire de l’UI en TDD !
Pour bien situer l’article, nous partons du principe que l’application testée est un Front-End autonome puisque nous n’allons pas aborder le fonctionnement des tests de composants côté Back-End.
Les tests de composants, c'est quoi ?
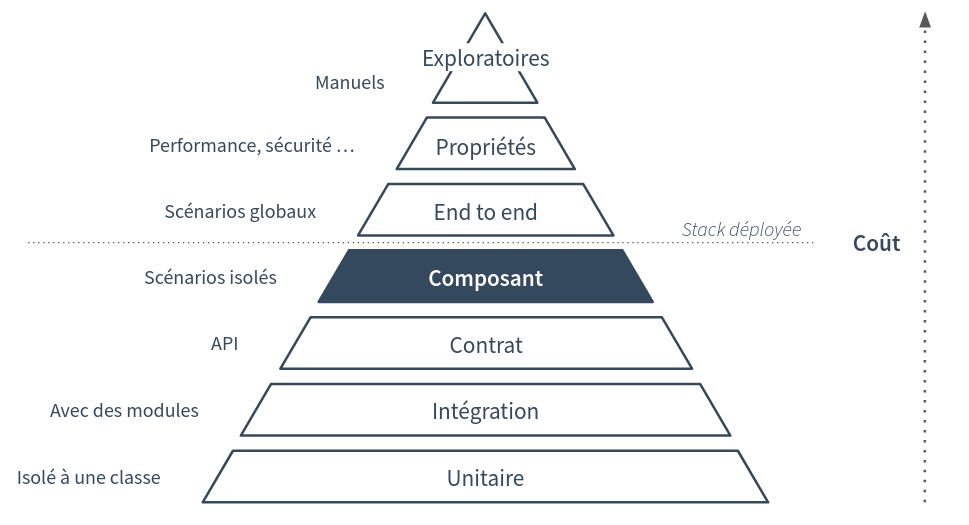
Leur place dans la pyramide des tests
Cette version de la pyramide des tests montre les différents types de tests existants. Ceux qui se trouvent au plus bas de la pyramide ont une granularité faible, ce sont les moins coûteux, ils sont plus faciles à mettre en place, à maintenir et donnent un feedback rapide au développeur lorsqu’ils sont joués. Les tests situés dans le haut de la pyramide sont moins nombreux car leur granularité est plus importante, ils nécessitent le déploiement d’un environnement complet, ont un coût de maintenance plus élevé, s’exécutent plus lentement et sont plus fragiles. Cependant, leur pertinence est tout aussi importante.
Les tests de composants sont les derniers tests qui ne nécessitent pas forcément le déploiement de la stack complète. Dans notre cas, nous pouvons les utiliser pour guider notre implémentation, pour faire du TDD.
Différence entre tests de composants et tests “end to end”
Cypress se présente comme un framework de “end to end testing”. Les tests “end to end” permettent de tester toute la stack de notre application. C’est-à-dire les interactions entre le Front-End, Back-End et la persistance pour une application monolithique ou l’ensemble de nos services dans un contexte distribué.
Les tests de composants permettent de créer des scénarios isolés pour tester le comportement d’un service en simulant son utilisation par des utilisateurs. Contrairement aux tests “end to end”, dans le contexte d’une application Front-End, les tests de composants utilisent une stratégie de tests à base de stubs pour reproduire les interactions avec le Back End ou les autres services.
Les autres outils
Cypress n’est pas le seul outil permettant d’effectuer ce type de tests. Le tableau ci-dessous propose un comparatif non exhaustif avec d’autres solutions.
Cette commande ajoute Cypress dans les node_modules de notre application et génère un dossier "cypress" contenant les éléments nécessaires pour l'utilisation de l'outil ainsi que des exemples.
Utilisation
Pour ouvrir Cypress, plusieurs possibilités :
Utiliser npx, un exécuteur de package inclus dans npm > v5.2 :
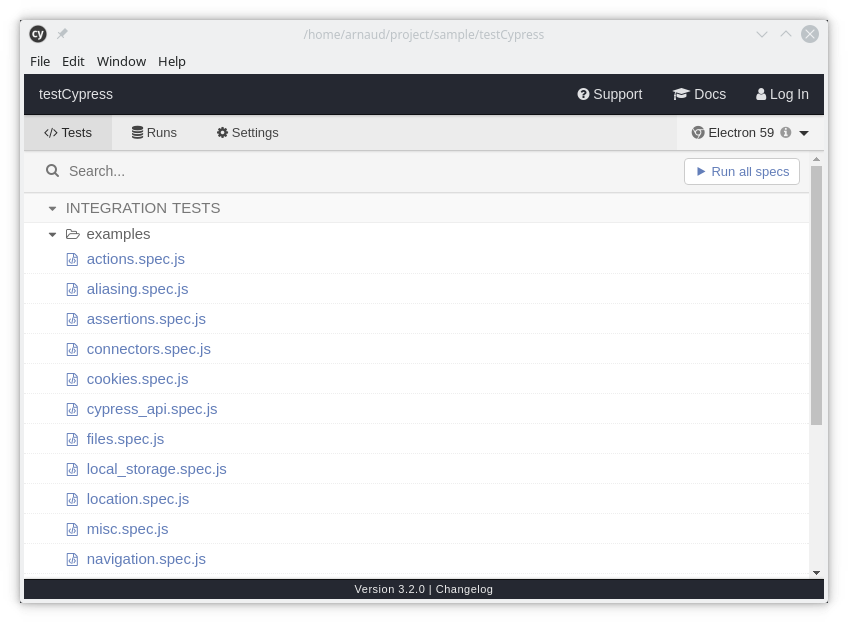
On retrouve l'ensemble des tests présents dans le dossier "integration". Pour jouer les tests, on clique sur le nom d'un test en particulier (qui correspond à un fichier) ou sur "Run all specs" pour tous les lancer.
Écrire son premier test de composants avec Cypress
À travers un exemple, nous allons montrer le fonctionnement de l’outil. La documentation de Cypress, plus exhaustive, permettra de compléter cet exemple.
Exemple
Voici donc le test d’une simple page composée du titre “Ma première utilisation de Cypress”.
describe("First simple page", () => {
it("Should have a title", () => {
cy.visit("/");
cy.get("h1")
.should("have.text", "Ma première utilisation de Cypress");
});
});
Si vous êtes familier avec les tests Front-End avec des frameworks comme Jest ou Mocha, vous retrouvez les expressions describe() et it(). Cypress se base sur la syntaxe de Mocha. On retrouve également context(), before(), beforeEach(), afterEach(), after(), .only() et .skip().
Comment ça fonctionne ?
Avec cy.visit("/");, on spécifie l’URL à visiter. La base URL (http://localhost:3000 par exemple) peut être configurée pour ne pas avoir à la spécifier à chaque fois. Cette configuration se fait dans le fichier cypress.json en spécifiant la baseUrl :
{
"baseUrl": "http://localhost:8080"
}
La commande cy.get("h1") cherche un élément du DOM. Ici nous cherchons directement l’élément titre h1 mais il est conseillé d’utiliser un sélecteur personnalisé. Il est également possible de chercher la classe ou l’id.
Finalement, notre assertion .should("have.text", "Ma première utilisation de Cypress") vérifie que l’élément trouvé contient bien le texte souhaité.
Stubber les routes
Comme nous l’avons vu, notre application peut interagir avec un serveur via une ou plusieurs API. Nous devons donc définir ce que retournent ces API externes via le système de Stubbing.
Cypress permet à l’aide de son cy.server() de stubber un serveur HTTP.
Avec cy.server({ enable: false }), vous pouvez arrêter votre serveur de stubs. C’est utile si vous avez envie de définir un stub à un moment et reprendre le fonctionnement normal de votre application par la suite.
Une fois le serveur lancé, il nous reste à stubber nos routes avec cy.route().
Pour récupérer le contenu du JSON retourné, il est possible d’utiliser les fixtures avec cy.fixture().
Les routes sont très faciles à stubber lorsque vous avez une ressource par URI (pour du REST par exemple), en revanche, Cypress ne propose rien pour gérer les stubs GraphQL. Une solution alternative est discutée dans l’issue GitHub suivante : https://github.com/cypress-io/cypress-documentation/issues/122.
Exemple classique :
cy.server();
cy.route({
method: 'GET', /* Route all GET requests */
url: '/user/*', /* that have a URL that matches '/users/*' */
response: { /* and force the response to be: { */
firstname: 'John', /* "firstname": "John", */
lastname: 'Doe', /* "lastname": "Doe" */
}, /* } */
}).as('user');
Exemple avec fixture :
cy.server();
// Set the response to be the user.json fixture
cy.route('GET', 'user/*', 'fixture:user.json').as('user');
L’appel à as permet de nommer notre route pour l’identifier et cy.wait() utilise cet identifiant pour attendre le résultat de la requête appelée par notre composant :
cy.server();
// Add route for the user John Doe
cy.route('GET', 'user/*', 'fixture:user.json').as('user');
// Profile page call current user
cy.visit('/profile');
// Wait the user result
cy.wait('@user');
// Check h1 is the combination of firstname and lastname
cy.get('h1').should('have.text', 'John Doe');
Conclusion
Bien que Cypress se définisse comme un framework de test “end to end”, cet outil nous permet d’écrire des tests de composants. Nous recommandons son utilisation pour toutes vos applications Front-End : il se marie bien avec Vue.js, Angular, React ...
Le fait de ne pas déployer notre stack nous permet de faire du TDD (et même de l’outside-in TDD), nous reviendrons donc là-dessus dans notre prochain article.
Alors que Java et PHP continuent de prédominer sur le marché des applications web, le besoin récurrent de proposer des produits toujours plus innovants avec un time-to-market réduit nécessite quelquefois de se tourner vers des solutions de développement plus accessibles afin de sortir une application en un temps record.
Parmi ces nouvelles solutions, deux s’en dégagent nettement : Python avec Django et JavaScript avec NodeJS.
Lorsque l’on parle de NodeJS, l’exemple typique que l’on utilise est l’application de chat car elle permet d’illustrer deux des avantages de cette solution : sa simplicité avec JavaScript permettant d’écrire rapidement un service de websocket et son module de clustering, facilitant la mise à l’échelle horizontale de l’application (une application NodeJS étant monothread, le module de clustering multiplie les instances de l’application pour répartir au mieux sa charge globale sur un CPU multicoeur).
Avec Node, on peut alors créer rapidement une application nécessitant peu de calculs et pouvant accueillir un nombre de requêtes à la seconde très conséquent.
Cependant, dans un contexte de production, réaliser une application fonctionnelle et performante n’est pas suffisant. Il faut également s’assurer que son code soit correctement écrit, structuré et testé.
Dans cette optique, de nombreux frameworks Node ont vu le jour, chacun répondant plus ou moins à ces critères. Parmi les plus connus, nous pouvons citer :
Express: Développé par la fondation NodeJS, Express peut être vu comme la principale boîte à outils de Node car en plus d’être la solution la plus populaire c’est aussi la base de la quasi-totalité des frameworks Node alternatifs.
Loopback: Développé par StrongLoop, une société IBM, Loopback est un framework spécialisé dans le création d’API REST. Son principal point fort étant son générateur de fichiers Typescript qui permet de générer toutes les couches de l’API à partir de la description de l’entité (comme le JDL de JHipster).
SailsJS: Permet d’écrire une application web JavaScript complète en se basant sur l’architecture MVC. Comme Loopback, l’idée derrière Sails est de proposer une solution calibrée pour du développement en entreprise par la génération automatique de fichiers.
Bien que ces solutions soient généralement une bonne aide pour aboutir à un projet de qualité, elles ne s'attardent pas toujours sur un aspect essentiel : proposer une architecture permettant de garder un projet correctement structuré quelle que soit sa taille.
Fort heureusement, il existe un framework tentant de répondre à cette problématique : NestJS.
La mise à l’échelle par l’architecture Angular.
Prenons un exemple de projet fraichement généré avec Express. Voici la structure du projet :
Et voici le point d’entrée de l’application :
var createError = require('http-errors');
var express = require('express');
var path = require('path');
var cookieParser = require('cookie-parser');
var logger = require('morgan');
var indexRouter = require('./routes/index');
var usersRouter = require('./routes/users');
var app = express();
// view engine setup
app.set('views', path.join(__dirname, 'views'));
app.set('view engine', 'pug');
app.use(logger('dev'));
app.use(express.json());
app.use(express.urlencoded({ extended: false }));
app.use(cookieParser());
app.use(express.static(path.join(__dirname, 'public')));
app.use('/', indexRouter);
app.use('/users', usersRouter);
// catch 404 and forward to error handler
app.use(function(req, res, next) {
next(createError(404));
});
// error handler
app.use(function(err, req, res, next) {
// set locals, only providing error in development
res.locals.message = err.message;
res.locals.error = req.app.get('env') === 'development' ? err : {};
// render the error page
res.status(err.status || 500);
res.render('error');
});
module.exports = app;
Que ce soit au niveau de son arborescence ou de son point d’entrée, on note que le projet est globalement basique et peu structuré.
Avec cette stratégie, n’importe quel développeur va pouvoir s’approprier le code rapidement pour y faire des ajouts. Cependant, partir d’un ensemble faiblement structuré risque de desservir l’évolution du projet car d’une part, il faudra s’assurer que sa structure reste cohérente à chaque ajout de fonctionnalités et d’autre part, il faudra factoriser le code du point d’entrée afin de ne pas accentuer son aspect fourre-tout (où se mélangent configuration globale du projet, gestion des routes et gestion des erreurs).
Pour limiter ce problème, il convient alors de définir des règles de structure et de nommage en amont de la réalisation du projet. Mais étant donné qu’il n’existe pas de consensus sur la stratégie à adopter, ces règles sont tacites et peuvent donc être facilement transgressées à chaque arrivée d’une fonctionnalité majeure ou d’une nouvelle personne sur le projet.
Idéalement, il faudrait un système qui soit suffisamment rigide pour borner explicitement la structure d’un projet NodeJS/Express tout en restant suffisamment simple pour ne pas alourdir inutilement les développements.
Dans le monde du front-end JS, le framework Angular propose une solution à ce problème.
Pour créer une bonne application Angular, on subdivise notre base de code sous la forme de modules (les NgModules) dans lesquels on va pouvoir déclarer des scopes afin de définir quelle portion de code est accessible depuis l’extérieur du module et quelle portion est réservée à un usage interne. L’application Angular ne sera alors plus hiérarchisée selon un ensemble de fichiers mais selon une succession de modules, ce qui permet d’augmenter facilement le nombre de fonctionnalités tout en ayant un code correctement isolé.
Avec les NgModules vient aussi l’injection de dépendances (ou DI). La DI permet d’instancier un service une unique fois au cours du cycle de vie de l’application. On peut donc écrire du code métier facilement accessible et réutilisable dans toute l’application.
En combinant modules et DI, Angular propose alors une structure rigoureuse, incitant le développeur à constamment réfléchir sur la manière dont il doit agencer son code afin de gérer aussi facilement une application possédant une dizaine de composants / services qu’une application en possédant une centaine.
Mais quel rapport avec NestJS ?
L’idée de NestJS est tout simplement de faciliter l’accès au framework Express en proposant une couche d’abstraction reposant sur l'architecture fondamentale d’Angular : les modules et l’injection de dépendances. Avec ce principe, NestJS est alors capable de proposer une plateforme de développement NodeJS que l’on peut facilement maintenir et mettre à l’échelle.
Par ailleurs, si ce framework se base sur l’architecture Angular, il est totalement agnostique sur le front-end ce qui signifie que l’on peut combiner cette solution avec un moteur de templating (ejs, hbs, pug, etc...) ou une application web (Angular, React, Vue, etc…).
Mise en pratique
Voici, la structure de base d’un projet NestJS :
Avec le point d’entrée suivant (main.ts), où AppModule est le module d’entrée de l’application :
import { NestFactory } from '@nestjs/core';
import { AppModule } from './app.module';
async function bootstrap() {
const app = await NestFactory.create(AppModule);
await app.listen(3000);
}
bootstrap();
Plutôt simple n’est-ce pas ? Admettons à présent que nous voulons créer une ressource REST avec un controller et un service.
Pour le service, nous aurons une classe munie du decorator @Injectable, permettant d’écrire une classe injectable :
import { Injectable } from '@nestjs/common';
@Injectable()
export class GreetingsApplicationService {
greet() {
return {
message: 'Hello World !',
};
}
}
Du côté du controller nous aurons une classe annotée @Controller pour pouvoir faire une classe injectable qui va gérer l’endpoint de notre ressource :
import { Controller, Get } from '@nestjs/common';
import { GreetingsApplicationService } from './geetings.service';
@Controller('greetings')
export class GreetingsController {
constructor(private readonly greetingsApplicationService: GreetingsApplicationService) {}
@Get()
greet() {
return this.greetingsApplicationService.greet();
}
}
Ici, notre ressource sera accessible dans une requête GET sur le endpoint /greetings. Afin de profiter au mieux de la modularité de notre application, on crée un module dédié :
import { Module } from '@nestjs/common';
import { GreetingsApplicationService } from './greetings.service';
import { GreetingsController } from './greetings.controller';
@Module({
controllers: [GreetingsController],
providers: [GreetingsApplicationService],
})
export class GreetingsModule {}
Que l’on injecte finalement dans le module principal :
import { Module } from '@nestjs/common';
import { AppController } from './app.controller';
import { AppService } from './app.service';
import { GreetingsModule } from './greetings/grettings.module';
@Module({
imports: [GreetingsModule],
controllers: [AppController],
providers: [AppService],
})
export class AppModule {}
Ce qu’il faut surtout retenir de cet exemple, c’est la manière dont sont déclarés et agencés les services et les controllers. Car si on a fait le choix de présenter ici un exemple de service REST, sachez que cette structure sera aussi valable si vous décidez de faire de la génération de vues, des Websockets ou du GraphQL.
Si les modules et la DI sont la pierre angulaire de NestJS, l'exemple ci-dessus montre que le framework reprend également le concept des Decorators et des Pipes. Ces éléments permettent de valider ou transformer de la donnée en amont d’une méthode, ce qui participe à la simplification du code.
D'une manière générale, si NestJS reprend autant de concepts Angular, c'est qu'ils proviennent de pratiques qui ont déjà fait leur preuves sur d'autres frameworks (par exemple, la DI et les Decorators sont courrament utilisés sur Spring). Ainsi, l'adoption de NestJS est globalement aisée.
Grâce à sa modularité, NestJS propose aussi un mode de fonctionnement distribuant les modules d'une application sous la forme de microservices :
Sans avoir la robustesse et la maturité d’une stack telle que Spring Cloud Netflix (pas d’équivalence à Eureka ou Zull en JS par exemple), cette solution permet de générer rapidement des microservices NodeJS bien architecturés. NestJS supporte aussi quelques messages brokers dont MQTT, Redis ou RabbitMQ.
Dépendances modulaires pour applications modulaires
En observant l’exemple précédent, vous avez sûrement remarqué qu’un projet NestJS semble bien plus avare en fonctionnalités qu’un projet Express fraîchement généré. Cette stratégie est voulue et correspond à un besoin particulier lorsque l’on fait du JS : éviter de surcharger le projet en dépendances.
Très souvent, écrire une application avec un framework revient à embarquer un nombre impressionnant de dépendances dans le dossier node_modules :
Legendary Apollo project programmer Margaret Hamilton, next to a printout of the node_modules directory listing for her first Hello World react app pic.twitter.com/tOsBifPtmI
— Thomas Fuchs (ret.) 🌵 (@thomasfuchs) March 7, 2019
Les développeurs de NestJS étant bien conscients de ce problème, ils ont adopté une stratégie où le projet de base contient le minimum vital pour écrire une application (Express inclus, ce qui est déjà beaucoup) et où chaque brique supplémentaire devra être ajoutée une à une afin que le développeur puisse garder la maîtrise des dépendances.
Ces briques sont, pour la plupart, des bibliothèques Node très populaires, pour lesquelles NestJS fournit des services injectables afin de pouvoir correctement les interfacer avec le code de l’application.
Parmis les extensions disponibles, on va trouver :
Des ORM/ODM avec TypeORM (pour le SQL/NoSQL) et Mongoose (pour Mongo).
Compodoc. Initialement créé pour Angular, cet outil permet de générer la documentation de votre application sous la forme d’une plateforme web. Si cet outil vous est inconnu, je vous invite très fortement à le découvrir.
Évidemment, le problème de ce système est que si le service injectable pour votre bibliothèque favorite est inexistant, il faudra alors le créer.
L’accessibilité avant tout
Au delà de la problématique d’architecture, l’objectif de NestJS est avant tout d’offrir une solution permettant de faire une maintenabilité globale d’une application NodeJS.
Dans ce contexte, on va donc retrouver :
TypeScript : une surcouche syntaxique permettant de faire du JavaScript typé afin de normer explicitement le code et faire de la détection d’erreur avant le runtime.
Jest : une plateforme de TU/TI développée par Facebook, plus d’info ici.
RxJS : La bibliothèque spécialisée dans la programmation réactive par le biais d’observables.
NestJS peut être également étendu avec Webpack pour faire du hot-reload.
L’inspiration de NestJS pour Angular se retrouve également dans le CLI qu’il met à disposition puisqu’en quelques lignes on peut générer un module complet :
nest g module greetings
nest g controller greetings
nest g service greetings
Le petit plus, c’est qu’en embarquant d’office Jest, le framework génère en même temps les fichiers sources et les fichiers de tests directement prêts à l’emploi.
Si vous avez l’habitude de travailler en TDD, vous aurez donc la possibilité d’écrire vos tests unitaires en amont de vos développements :
En revanche, le générateur de fichiers de NestJS est bien plus limité que celui de Loopback ou Sails (pas de génération automatique d’API ou de page web) ce qui nécessite d’écrire plus de code manuellement.
NestJS, une solution pour des projets à grande échelle
Avec une bonne popularité et un support actif (16K+ étoiles sur le repo Github avec des releases hebdomadaires), l’orientation minimaliste de NestJS et sa scalabilité semblent être une solution de choix dès lors que l’on veut aborder NodeJS.
Mais pour chaque projet vous aurez besoin de mettre en relation vos objectifs de qualité avec le temps que vous allez allouer à vos développements.
Par exemple, si votre objectif est simplement d’écrire une API REST, adopter Loopback et son générateur d’entités vous permettra d’arriver à vos fins plus rapidement et tout aussi efficacement. De la même manière, Sails et son très grand panel d’outils permettent de produire une plateforme web en très peu de temps.
Alors, que faire avec NestJS ?
Et bien comme nous l’avons vu au cours de cet article, l'intérêt de ce framework se situe sur des projets où la rapidité du développement peut être mise un peu en retrait au profit d’une meilleure maintenabilité. Le cas typique serait le développement d’une application avec une base fonctionnelle simple qu’il faudra régulièrement incrémenter tout en assurant une bonne robustesse technique.
De plus, NestJS est également un très bon framework pour débuter dans le développement d’application NodeJS. En reprenant les concepts Angular, NestJS peut à la fois intéresser les développeurs front-end souhaitant s’initier au développement back-end, mais aussi les développeurs Java/PHP qui voudraient explorer une solution de développement simplifiée.
Pour finir, si vous souhaitez voir un projet NestJS en action, je vous propose une application exemple qui génère une API REST enrichie avec de nombreuses briques (Authentification, entités SQL, validation de formulaires, confs par environnement, etc...) afin d’avoir un aperçu des possibilités offertes par ce framework.
L’objet de ce document est de fournir des recommandations pour mieux utiliser, configurer, opérer et superviser la solution Snowflake dont Ippon est partenaire depuis début 2019.
Ces recommandations ne remplacent pas une étude détaillée pour répondre du mieux possible à vos besoins.
Il faut profiter du fait que l’utilisation de Snowflake ne soit pas encore généralisée dans un groupe pour mettre en place les bonnes règles de gouvernance.
Ces règles doivent permettre une meilleure organisation des objets, une sécurité adaptée et rendre possible la rétro-facturation si nécessaire.
Pour mieux comprendre les spécificités de Snowflake, cet article de Christophe Parageaud est à votre disposition sur le blog Ippon.
Sujets étudiés
Choix de l’édition de Snowflake
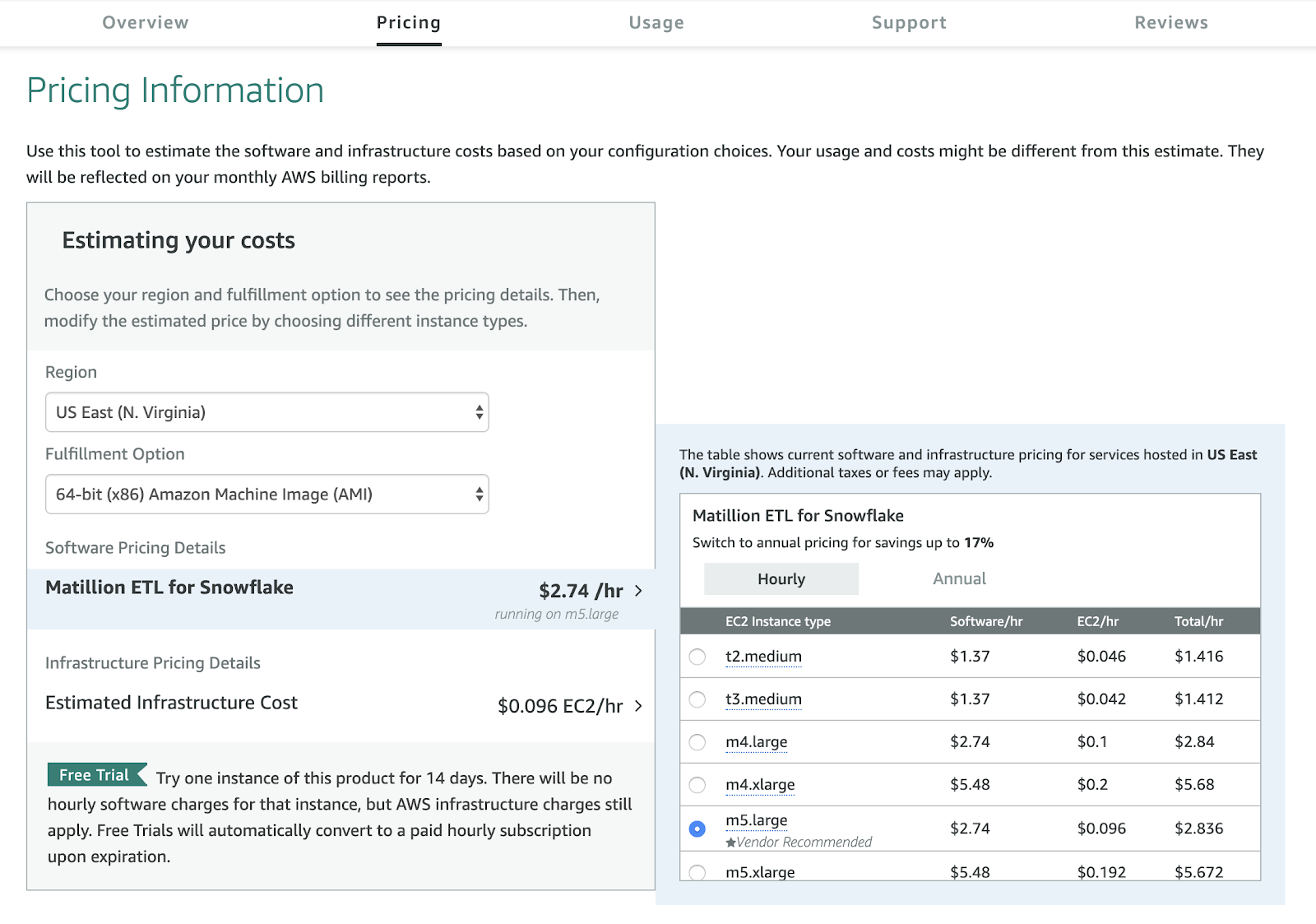
Les éditions suivantes sont disponibles (avec indication du prix de compute par édition) :
Standard - $2.50 / crédit
Premier - $2.80 / crédit : ajoute le support 24x365
Enterprise - $3.70 / crédit : ajoute possibilité de 90 jours de Time Travel (qui permet d’accéder des versions précédentes des données), multi cluster warehouse et les vues matérialisées
Enterprise for Sensitive Data - $5 / crédit : augmente la sécurité notamment grâce au Private Link, peut être nécessaire pour les données RH
Virtual Private Snowflake - sur demande : si on veut être mono-tenant
À ces prix il faut ajouter $23 / TB / mois pour le stockage, dans l’hypothèse d’un contrat capacitaire (Achat de crédits à l’avance).
La documentation est disponible ici et le pricing ici.
Recommandation :
80% des clients de Snowflake utilisent l’édition enterprise car elle permet d’utiliser toutes les fonctionnalités de Snowflake comme le Time Travel ou le Private Link (pour connecter Snowflake à votre propre VPC, en option) et de bénéficier de toutes les nouvelles fonctionnalités rajoutées chaque mois.
Si on venait à stocker de plus en plus de données critiques, on orientera le choix vers la version Enterprise for Sensitive Data, notamment pour disposer de la fonctionnalité de gestion de clés de cryptage à 3 parties.
Séparation des comptes
Un compte Snowflake correspond à une ligne de facturation et à une région de déploiement chez un fournisseur Cloud (AWS ou Azure, aujourd’hui, GCP annoncé pour début 2020).
Deux approches sont possibles :
mono-compte :
Description : le groupe gère une seule souscription utilisée pour ses besoins mais aussi ceux des filiales.
Avantages : simplicité d’utilisation et de partage des données par création de vues ou de “zero-copy-cloning” (explication au paragraphe suivant) par exemple.
Inconvénients : si besoin de refacturation, il faut suivre les usages et pouvoir les facturer en interne.
multi-comptes :
Description : On crée un compte pour le groupe puis un compte par filiale. On peut imaginer un seuil d’utilisation à partir duquel cela est pertinent.
Avantages : la séparation des comptes entraîne une séparation de la facturation
Inconvénients : obligation d’utiliser la fonction de data sharing pour partager des données du groupe vers les filiales.
Recommandation :
D’après l’utilisation actuelle, il semble préférable de continuer à utiliser un seul compte.
Par contre, le nommage des objets doit permettre la séparation des objets dans des comptes différents le jour où cela s’avèrera nécessaire.
On utilisera donc un préfixe [COMPANY] qui composera le nom de l’objet database.
De la même manière, il faudra utiliser ce préfixe pour le nommage des rôles (c.f. paragraphe sur les rôles).
Séparation des environnements
La séparation des objets entre les environnements de DEV, de TEST et de PROD est primordiale.
Avec Snowflake, il ne s’agit pas de séparer ces environnements avec plusieurs comptes mais plutôt d’utiliser une nomenclature adaptée.
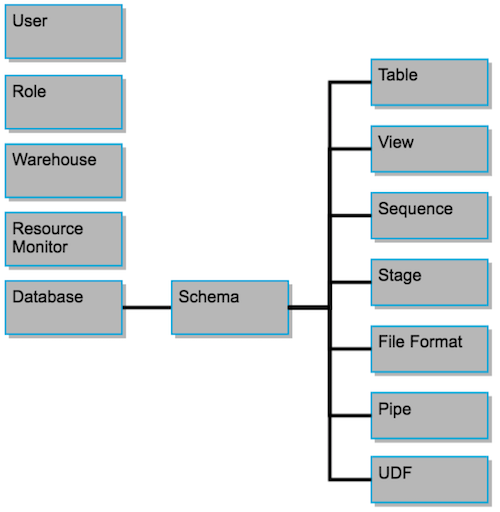
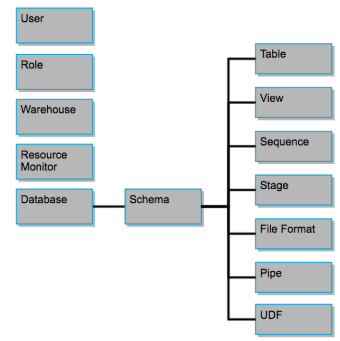
Rappel de la hiérarchie des objets avec Snowflake :
Recommandation :
Utiliser un suffixe désignant l’environnement [ENV] dans la règle de nommage de l’objet database qui aura donc la forme [PREFIXE]_[ENV]_DB.
Par exemple :
PROD_DB
TEST_DB
DEV_DB
FILIALE_PROD_DB
FILIALE_TEST_DB
FILIALE_DEV_DB
Pour gérer les données entre ces différents environnements, vous pouvez utilisez l’excellente fonctionnalité appelée “fast-cloning” ou “zero-copy-cloning” telle qu’elle est décrite dans cet article.
Couplé à un outil de gestion de cycle de vie du modèle de données comme Sqitch, on peut construire un solide pipeline de CI/CD.
Séparation des domaines fonctionnels
Comme vu dans la figure précédente, les schémas permettent de regrouper les objets au sein d’une database.
Recommandation :
Pour séparer les domaines fonctionnels, nous préconisons de créer différents schémas.
Le nom du schéma ne portera pas la mention de l’environnement, qui est déjà portée par la database.
Par exemple :
FOURNISSEURS_SCH
CLIENTS_SCH
Séparation des différentes workloads
Ce qu’on appelle “workload” correspond à une catégorie d’usage.
Avec Snowflake, on peut séparer les workloads grâce aux virtual warehouses (WH).
Il est intéressant de les séparer pour trois raisons :
Dimensionnement : adapter la puissance de calcul en fonction des besoins
Facturation : savoir combien de crédits consomme chaque virtual warehouse
Isolation : pour que les requêtes des uns n’impactent pas celles des autres
Au niveau du coût c’est équivalent car les WH non utilisés ne coûtent rien dès lors qu’il se sont automatiquement arrêtés (au bout de 5 minutes minimum sans requête).
On retrouve régulièrement les 4 workloads suivantes :
LOAD : Le chargement des données planifié quotidiennement.
EXTRACT : Le déchargement des données (vers un outil de data visualisation par exemple) planifié quotidiennement.
QUERY : L’interrogation de Snowflake par les data scientists et data analysts pour faire de l’exploration de données.
LIVE : L’interrogation de Snowflake par des outils de data visualisation branchés en live (comme par exemple Superset).
Nous préconisons de séparer ces 4 workloads sur 4 virtual warehouses et ce pour chaque société et environnement pour lesquels cette workload serait utile.
Par exemple, si une filiale ne consomme que des données qui ont déjà été chargées niveau groupe, elle n’aura pas de WH de type LOAD.
Exemple :
Pour le groupe, on aurait les virtual warehouses suivant :
PROD_LOAD_WH
PROD_EXTRACT_WH
PROD_QUERY_WH
PROD_LIVE_WH
Pour une filiale, qui ne fera à priori pas de live dans un premier temps, on aura seulement :
FILIALE_PROD_LOAD_WH
FILIALE_PROD_EXTRACT_WH
FILIALE_PROD_QUERY_WH
Sur les environnements de DEV et TEST, on ne créera que les virtual warehouses nécessaires.
Et pour les filiales qui n’auraient que de faibles besoins, on pourrait commencer en utilisant les virtual warehouses du groupe.
Gestion des rôles
Dans Snowflake on gère la sécurité en attribuant des rôles aux utilisateurs.
Recommandation :
Nous préconisons d’avoir par défaut :
1 rôle ADMIN par database, par exemple
PROD_DB_ADMIN_RL
FILIALE_DEV_DB_ADMIN_RL
2 rôles par schémas, un rôle ADMIN et un rôle READ :
FOURNISSEURS_SCH_ADMIN_RL
FOURNISSEURS_SCH_READ_RL
On notera que le type d’objet (DB ou SCH) a été conservé dans le nom, ainsi on sait tout de suite sur quel niveau de la hiérarchie d’objet on se positionne.
Convention de nommage des objets
Le nom des tables doit si possible décrire le domaine fonctionnel des données qu’elle contient.
Par exemple : CODES_PAYS
C’est pareil pour le nom des vues mais on suffixera le nom avec _VIEW.
Par exemple : CLIENTS_NOUVEAUX_VIEW
Méthode de partage des données entre les filiales
Pour partager les données entre les filiales, la mise à disposition de vues est une bonne solution.
Si un jour on crée plusieurs comptes Snowflake, on pourra utiliser le data sharing.
Suivi des coûts
Pour suivre les coûts plus finement (par exemple : par utilisateur, par rôle) que ce qui est proposé dans l’interface de Snowflake (par warehouse), on pourra construire des tableaux de bords avec un outil comme Superset.
Par exemple la vue SNOWFLAKE.INFORMATION_SCHEMA.WAREHOUSE_METERING_HISTORY permet de suivre les crédits consommés sur chaque virtual warehouse.
Une meilleure connaissance des coûts permet de mieux prévoir les crédits à provisionner.
Conclusion
Avec l’ensemble de ces recommandations, on peut atteindre une meilleure organisation des objets avec en particulier une bonne identification des environnements et des différentes filiales. L’utilisation des rôles permet d’assurer un niveau d’accès fin aux utilisateurs.
La séparation des virtual warehouses permettra de mieux séparer les coûts d’utilisation de Snowflake et facilitera le reporting financier.
S'il est une question qui revient très souvent lorsqu'on parle de tests c'est le taux de couverture que les projets doivent atteindre. Il est même maintenant courant de voir des demandes de 80% de taux de couverture dans les definitions of done ou même dans les contrats.
Ces seuils sont mis en place pour apporter de la qualité aux projets, c'est en tout cas l'intention initiale et elle est tout à fait louable. Malheureusement, le taux de couverture, utilisé ici comme un objectif et non plus comme un indicateur devient un piètre moteur pour l'amélioration de la qualité du code.
Dans cet article je vais partager mon point de vue de développeur sur les dérives de l'utilisation de cette metric mais aussi, et surtout, proposer des alternatives pour répondre à ce réel besoin : faire de meilleurs tests pour, au final, délivrer de meilleures solutions.
Cet article s'adresse aux développeurs mais aussi aux chefs de projets, scrum masters, commerciaux et à toutes les personnes prenant part aux projets sans faire de code.
À quoi servent les tests ?
Avant de nous lancer dans l'écriture de meilleurs tests et dans le jugement de leur qualité il convient de rappeler leur utilité. Il existe de nombreux types de tests chacun servant un dessein différent. Une représentation très pratique pour en comprendre certains est le quadrant des tests agiles :
Ce schéma se lit sur deux axes, ainsi les tests unitaires sont en rapport avec la technologie et aident au développement. Dans la majorité des cas, lorsqu'on parle de taux de couverture on parle des tests de la partie gauche qui vont inclure :
Les tests unitaires : Un élément (class) isolé a-t-il le comportement attendu ?
Les tests sociaux : Deux éléments fortement couplés ont-ils le comportement attendu ?
Les tests d'intégrations : Mon code s'intègre-t-il correctement avec des composants externes (Framework, persistence, WebServices, …) ?
Les tests de contrats : Une API ayant fonctionné fonctionne-t-elle toujours correctement ?
Les tests de composants : La logique métier de mon composant isolé du reste du système est-elle correcte ?
Les tests end-to-end : Mon système a-t-il le comportement attendu ?
Lors de l'écriture de chaque test il faut donc s'assurer que l'on répond à un besoin en utilisant le bon type de test et les bons outils. Utiliser un marteau pour planter des vis entraînera, au mieux, des tests inutiles et, au pire, des tests compliqués à maintenir qui vont réduire la vélocité.
On rencontre ici un premier biais à l'utilisation d'un objectif de couverture : fixer un objectif de couverture arbitraire va pousser les développeurs à faire des tests pour respecter ce taux, pas forcément pour répondre à un besoin.
Même si la majorité du temps on reste dans le cadre de la loi de Goodhart en détournant une mesure pour en faire un objectif. Dans certaines situations extrêmes l'objectif va être détourné avec des développeurs qui vont pousser du code et des tests parfaitement inutiles pour augmenter artificiellement le taux de couverture. On parle alors d’effet cobra.
Au même titre que tout autre code les tests doivent être faits s'ils apportent de la valeur que ce soit pour la fabrication du code ou pour en assurer la pérennité.
Doit-on tout tester ?
Fixer un taux de couverture arbitraire sur un projet implique qu'à terme il faudra tout tester, ou presque.
Il existe cependant au moins deux cas où faire des tests a très peu de sens :
Lorsque des éléments d'un Framework (ou du langage) rendent les tests très coûteux à mettre en place. Ce coût peut venir de l'effort nécessaire pour pouvoir faire le test ou du temps d'exécution des tests. Si ce coût est bien plus élevé que la valeur du test alors sa mise en place n'a pas de sens. On rencontre généralement ce cas pour la gestion de certaines erreurs levées par des composants externes qui sont difficilement simulables et dont le code de gestion est, au final, très simple ;
Lorsque le code que l'on veut tester a été généré, que ce soit par notre IDE ou par un autre outil. Par exemple vouloir tester une méthode equals générée automatiquement va rapidement demander beaucoup de temps et de cas de tests pour une valeur très faible.
Faire du code c'est faire preuve de pragmatisme : les efforts déployés doivent être en cohérence avec la valeur produite. Ainsi passer une heure pour tester des POJO générés n'a pas vraiment de valeur mais utiliser cette même heure pour s'assurer que l'on traite correctement les erreurs venant de la base de données (par exemple) en aura beaucoup plus.
Dans cette optique, si on admet qu'il n'est pas intéressant ou utile de tester tout le code on va rapidement se retrouver dans une impasse en imposant un taux de couverture minimal.
Que montre le taux de couverture ?
Imposer un taux de couverture minimal implique de comprendre cet indicateur, ce qui n'est pas si simple... On distingue plusieurs types de taux de couverture, en voici quelques-uns :
La couverture de lignes : les tests sont lancés, chaque ligne sur laquelle un test passe est considérée comme couverte ;
La couverture de branches : les tests sont lancés, chaque branche du code dans laquelle un test passe est considérée comme couverte. Par exemple, un "if(titi && toto)" contient 4 branches (false && false, false && true, true && false, true && true) mais la première et la seconde sont identiques en terme d'exécution ;
La couverture de mutation : Un changement est fait dans le code (changement d'une condition, d'une valeur, …) et on lance les tests passants dans le code modifié. Si les tests passent encore (dans ce cas on dit qu'ils survivent) alors le cas n'est pas couvert.
Quand on parle de taux de couverture on parle des deux premiers types : dans quelles parties de mon code passent mes tests ?
Si on prend le célèbre kata GildedRose voici un test en Java avec 100% de couverture de lignes et de branches :
public class GildedRoseTest {
@Test
public void testGildedRose() {
GildedRose rose = new GildedRose(defaultItems());
for (int day = 0; day < 50; day++) {
rose.updateQuality();
}
}
private Item[] defaultItems() {
return new Item[] { new Item("+5 Dexterity Vest", 10, 20),
new Item("Aged Brie", 2, 0),
new Item("Elixir of the Mongoose", 5, 7),
new Item("Sulfuras, Hand of Ragnaros", 0, 80),
new Item("Sulfuras, Hand of Ragnaros", -1, 80),
new Item("Backstage passes to a TAFKAL80ETC concert", 15, 20),
new Item("Backstage passes to a TAFKAL80ETC concert", 10, 49),
new Item("Backstage passes to a TAFKAL80ETC concert", 5, 49) };
}
}
En regardant le taux de couverture on va donc penser que l'on peut modifier sans risque la logique en ayant l'assurance d'avoir un test en erreur en cas de régression. Malheureusement, ce test ne valide quasiment rien (uniquement l'absence d'exceptions dans le traitement).
Certes ici le problème est évident ! Malheureusement, dans des cas plus complexes, il est beaucoup plus compliqué de détecter ce genre de défaut pour un humain. On s'attend donc à avoir cette information avec la couverture de tests mais ici seule la couverture de mutations détecte le problème.
On pourrait se dire qu'il faut alors se baser sur la couverture de mutation pour savoir si l’on teste vraiment des choses. Attention cependant : la couverture de mutation est très coûteuse (chaque test étant rapidement lancé plusieurs centaines de fois) et il est donc souvent contre-productif de vouloir la généraliser.
La couverture de mutation ne va aussi valider qu'un nombre fini de mutations, elle n'assure pas non plus une couverture complète !
Mettre en place une analyse systématique de la couverture de mutation sur des éléments métiers critiques est cependant une bonne idée.
Bien qu'étant un indicateur intéressant le taux de couverture ne permet pas de mesurer :
La pertinence des tests : comme nous l'avons vu, il est possible de faire des tests qui ne testent rien mais il est aussi tout à fait possible de faire des tests qui n'ont aucune valeur (alors qu'ils valident effectivement des comportements) ;
La testabilité de la solution : au prix de beaucoup d'efforts il est toujours possible de passer dans du code avec des tests. Ce n'est pas parce que des tests passent dans du code que ce code est testable ;
La pérennité des tests : des tests sur une solution qui n'était, au final, pas testable vont rapidement ralentir la vélocité en n'apportant aucune qualité. On va alors se retrouver dans des situations de suppression ou de désactivation des tests car, effectivement, ils n'apportent rien et ne sont plus pertinents pour la solution ;
La qualité des tests : De manière générale le taux de couverture ne donne aucune indication sur la qualité des tests qui ont été écrits. Ce n'est pas le but de cet indicateur et il ne doit pas être utilisé pour juger cela !
Ignorer la couverture
Paragraphe à destination des techniciens !
Accepter de ne pas tout tester doit se faire de manière consciente et les classes et methods que l'on choisit de ne pas tester ne doivent pas polluer nos rapports de couverture.
Il est courant de voir des classes ou des packages ignorés dans les analyses de couverture en utilisant la propriété sonar.coverage.exclusions avec le sonar-maven-plugin dans nos pom.xml. Malheureusement, à l'heure où j'écris ces lignes, il n'est pas encore possible d'ignorer des methods de cette manière (même si cela devrait se faire de cette manière à terme).
Il est cependant possible d'ignorer l’analyse de couverture sur des éléments ayant une annotation particulière ! Pour ce faire il faut commencer par créer une annotation runtime dans notre projet et mettre Generated dans le nom de cette annotation :
@Retention(RetentionPolicy.RUNTIME)
@Target({ElementType.METHOD, ElementType.TYPE})
public @interface Generated {
}
Vous pouvez nommer cette annotation IdeGeneratedForMyProject si vous le souhaitez. Il faut simplement qu'il y ait Generated dans son nom et qu'elle soit en rétention RUNTIME.
Il faut ensuite configurer l'analyse de couverture de manière plutôt classique dans notre pom.xml :
De cette manière les classes et methods que vous allez annoter seront exclues des calculs de taux de couverture et il sera alors beaucoup plus aisé d'exploiter les rapports.
On voit aussi souvent l'utilisation de commentaires pour exclure du calcul de couverture certaines portions de code. Je n'aime pas vraiment cette manière de faire : je veux connaitre le code que j'ai fait et qui n'est pas couvert ! Même lorsque ce code n'est pas testable je veux garder en tête qu'un refactoring est nécessaire sur cette portion de la solution.
Quelles solutions ?
La première chose à faire est d'utiliser ce taux de couverture pour ce qu'il est : un indicateur. Utilisé comme tel, il a beaucoup de valeur pour les développeurs que ce soit pendant l'écriture des tests ou tout au long de la vie du produit. Pendant l'écriture il permet de s'assurer :
Que l'on n’a pas oublié un cas essentiel dans nos tests ;
Que les cas qui ne sont pas testés le sont de manière consciente et admise.
Et pendant la vie du produit il est intéressant de suivre la tendance de ce taux et non pas sa valeur absolue ! Et c'est bien là un premier élément de réponse : bloquer du code lorsqu'il a moins de XX% de couverture va entraîner de nombreux biais mais bloquer du code si la couverture est moins bonne que précédemment s'inscrit dans une démarche d'amélioration continue. Même si le nouveau code produit n'est pas testable il sera toujours possible d'ajouter des tests ailleurs. Enfin, tant qu'on se concentre sur le code ou l'on veut calculer la couverture en ignorant le code généré.
Ce n'est cependant qu'une potentielle réponse (qui ne sera pas adaptée dans tous les contextes) à une toute petite partie du problème : le point essentiel ici étant de pouvoir juger de la qualité des tests qui sont faits sur la solution.
Pour juger de leur qualité il est primordial d'évaluer leur valeur :
Les tests ne doivent pas baisser la vélocité ; ainsi des phrases telles que "Je n'ai pas fait les tests, je n'ai pas eu le temps" sont des indicateurs très forts d'un problème plus profond. De la même manière une baisse générale de la vélocité dans le temps est certainement un signe de manque de qualité ;
Les tests ne doivent pas gêner le quotidien sans raison : "Les tests sont en erreur mais c'est normal" est une remarque qu'il est essentiel de traiter au plus tôt ;
Les tests doivent apporter une forte assurance dans la qualité de la solution. Si vos tests passent, la solution fonctionne, ça ne veut pas dire qu'elle fait ce qu'elle doit faire, simplement qu'elle fait ce que vous attendez qu'elle fasse. Si votre produit plante régulièrement alors que tous les tests sont au vert vous avez un problème.
Ce sont là 3 indicateurs (le ressenti de l'équipe étant un indicateur très important à prendre en compte) qui vous donneront une bien meilleure vision de l'état de vos tests.
Si vous détectez ce type de situation il existe de nombreuses solutions pour apporter de la valeur à vos tests et pour apprendre à bien vivre avec eux au quotidien !
La bonne méthode pour le bon besoin
Un premier point essentiel à prendre en compte est, comme toujours, d'utiliser des outils et méthodes adaptés au besoin. Les tests répondent principalement à deux besoins :
Ils permettent l'émergence de designs offrant une réponse adaptée ;
Ils valident que l'application fonctionne de la manière définie par les tests. Dans tous les cas ils ne valident pas réellement le bon fonctionnement de l'application puisqu'il est très facile de faire, en toute bonne foi, des tests qui ne valident pas le bon comportement (mais c'est un autre sujet).
Même si le premier point est essentiel ce n'est pas le sujet de cet article :). En ce qui concerne la validation du fonctionnement il faut utiliser les tests pour ce pour quoi ils sont faits :
Valider
Tests
Méthode
Définit par
L'implémentation technique dans le détail (gestion de chaque erreur etc…)
Bien évidement toute personne impliquée sur le projet doit participer aux tests je n'indique ici que les acteurs principaux de chaque famille de test.
Il n'y a pas de choix à faire ici, chacun de ces types de tests doit être mis en place pour permettre une couverture complète et donc une validation de la solution.
L'équilibre pour maintenir la valeur des tests
Réussir à équilibrer les tests est sans doute plus compliqué que faire les tests en eux même. En fait, lorsqu'un projet rencontre des problèmes de fiabilité la tendance est souvent d'ajouter des tests end-to-end sans ajouter d'autres types de test. Dans des cas extrêmes les campagnes end-to-end peuvent même :
Prendre plusieurs jours pour être jouées ;
Demander de très nombreuses d'heures d'analyses humaine pour supprimer les faux positifs ;
Demander du travail à plein temps pour être maintenues.
Bref, des campagnes qui auront coûté des fortunes et qui ne seront pas utilisées. Des tests ne sont utiles que s'ils apportent du confort dans le quotidien de tout le monde et pour ce faire la pyramide de tests doit être équilibrée :
Une pyramide de tests mal équilibrée générera plus de frustration et de perte de temps qu'elle ne sera bénéfique à l'équipe et à la solution !
Les tests ne sont pas la solution à un manque de fiabilité
Nous arrivons maintenant à la conclusion de cet article et je crains qu'elle ne déplaise…
En fait, en demandant un taux de couverture de tests minimal on cherche à fiabiliser nos solutions. Malheureusement, s'ils n'existent pas, les tests ne seront pas la solution à un manque de fiabilité.
Je ne suis pas en train de dire que les tests ne valident pas le fonctionnement. Ce que je veux dire ici c'est que forcer la rédaction de tests de quelque manière que ce soit n'améliorera en rien la fiabilité d'une solution.
Faire des tests apportant de la valeur est tout sauf une tâche aisée, dans une équipe qui ne rédige pas de tests forcer leur réalisation n'apportera probablement aucune valeur.
La solution ici n'est pas de demander X tests supplémentaires mais d'accompagner l'équipe pour que les méthodes évoquées plus haut (TDD et ATDD) deviennent naturelles et qu'il ne soit plus envisageable de travailler d'une autre manière.
Bien sûr cela prendra du temps et de l'énergie. Dans certains cas même ce ne sera pas possible mais dans tous les cas le jeu en vaut la chandelle ! Une équipe qui fait naturellement des tests avant de faire son code alliera vélocité et qualité des développements tout en apportant une réponse vraiment adaptée au besoin.
Il existe bien des manières d'accompagner une équipe dans cette transformation en commençant par intégrer un tech-lead rompu à ces pratiques mais, dans tous les cas, imposer 80% de couverture dans les contrats n'améliorera pas la fiabilité de la solution.
Je vais présenter dans cet article la fonction Azure Security Center et vous montrer quelques-unes de ses fonctionnalités.
Présentation de la solution Azure Security Center
Azure Security Center est une console permettant de centraliser la gestion de la sécurité et offre des outils de protection avancée contre les menaces sur le Cloud de Microsoft Azure.
Afin d’activer cette fonctionnalité, il faut ouvrir une session sur votre portail Azure avec un compte ayant les privilèges Security Admin
Voici le lien vers Microsoft expliquant les rôles RBAC :
Rechercher ensuite Azure Security Center où cliquer sur Azure Security Center dans le volet gauche de la console d’administration.
Vous avez la possibilité de la tester gratuitement durant 30 jours
Cliquer ensuite sur Start trial afin d’activer la fonctionnalité.
Lancer ensuite Azure Security Center. La vue globale vous donne la visibilité sur la santé de votre infrastructure et les possibles failles de sécurité que vous devrez corriger.
Je vous invite à cliquer ensuite sur Security Alert sous le menu Smart Protection. Nous pouvons voir ci-dessous une attaque Brute Force sur un de nos serveurs d’infrastructure.
Une attaque par force brute est une tentative visant à craquer un mot de passe ou un nom d'utilisateur via un processus d'essais et d'erreurs.
De ce fait une personne a essayé à plusieurs reprises de se connecter sur ce serveur en essayant différents login et mot de passe sans succès.
Les alertes dans Azure Security Center sont classées en différentes catégories, High, Medium et Low
La liste contient les informations suivantes :
Le nom de l’attaque,
Le nombre de fois ou la ressources a été attaqué
L’heure où celle-ci a été détecté
L’environnement
Le statut
La sévérité
En cliquant sur celle-ci nous avons une explication plus détaillée sur l’attaque détectée par Azure Security Center
Ce qui est intéressant avec Azure Security Center, c’est qu’il nous donne des pistes de remédiation sur les attaques rencontrées
Mise en place de Azure Sentinel
Nous allons maintenant mettre en place une alerte personnalisée. Dans la console Azure Security Center. Pour cela, cliquer sur Custom Alerte Rule sous le menu Threat Protection.
Cliquer ensuite sur Launch Azure Sentinel afin de la mettre en place.
Microsoft Azure Sentinel est une solution SIEM (security event information management, « Gestion de l'information des événements de sécurité ») native dans le cloud, offrant une analytique avancée de l'intelligence artificielle et de la sécurité.
Lorsque vous souhaitez activer une fonctionnalité Azure, vous devez faire attention si celle-ci est disponible dans la région de votre ressource groupe sans quoi vous ne pourrez la mettre en place.
Azure Sentinel se base sur un espace de travail Azure Log Analytics pour fonctionner, il faut donc s’assurer lors de la création de cet espace que l’on soit dans une région ou Azure Sentinel est disponible.
Log Analytics va nous permettre de collecter la donnée, en l’occurrence les logs et de les analyser avec Azure Sentinel.
Voici le lien pour connaître la disponibilité des services Azure par région.
Maintenant que notre espace de travail Log Analytics est créé dans la bonne région, nous cliquons sur Add Azure Sentinel
Création d’une alerte personnalisée
Nous cliquons ensuite sur Analytics sous Configuration puis sur Add afin de créer notre alerte.
Nous allons maintenant créer une règle, dans notre exemple, nous seront alerté si trop d’objets sont créés dans notre souscription.
Ci-dessous le code :
AzureActivity
| where OperationName == "Create or Update Virtual Machine" or OperationName == "Create Deployment"
| where ActivityStatus == "Succeeded"
| make-series dcount(ResourceId) default=0 on EventSubmissionTimestamp in range(ago(7d), now(), 1d) by Caller
Renseigner les champs suivants, nécessaires à la création de votre alerte :
Nom de la règle
Description de l’alerte
Spécifier le code de l’alerte
Spécifier ensuite le trigger d’alerte
Puis valider la règle
Il est possible d’installer les plugins Azure Sentinel afin de le connecter avec l’Active Directory. Pour cela, cliquer sur DashBoard puis spécifier les plugins qui vous intéresse en cliquant sur Install dans le volet de droite.
Une fois le plugin installé, cliquer sur View DashBoard
Il est possible de connecter Sentinel avec nos outils en cliquant sur Data Connector sous le menu Configuration puis sélectionner Azure Security Center
Une fois les tableaux de bords installés, il est possible de lancer les requêtes prédéfinies afin d’identifier des menaces. Pour cela cliquer sur Hunting dans le bandeau de gauche, sélectionner la requête souhaitée puis cliquer sur Run Query pour l’exécuter.
Retourner maintenant sur Azure Security Center, en cliquant sur Azure Security Center dans le menu de gauche. Cliquer sur Secure Score sous Policy Compliance puis cliquer sur View Recommandations
Cette vue vous donne les recommandations de Microsoft afin de sécuriser votre infrastructure Cloud avec les points à corriger.
En cliquant sur un des points, ici le MFA, vous avez une analyse plus approfondie, avec la description de l’alerte, les informations et les corrections à apporter.
Cliquer ensuite sur Regulatory Compliance. Cette vue, vous permet de connaître les exigences et les corrections à apporter afin d’être en conformité avec différentes normes de sécurité
Sous Resources Security Hygiene, cliquer sur Recommandations. Les recommandations listées ici reprennent l’ensemble des sous-menu (Compute, Apps,Networking, IAM…)
Mise en place d’une règle automatisée
Nous allons ici exécuter un playbook pour configurer des réponses automatisées dans Sentinel. Pour cela, cliquez sur Playbook sous le menu Automation Orchestration
Cliquer ensuite sur Add Playbook afin de construire votre alerte personnalisée.
Après quelques minutes votre Logic Apps est disponible.
Cliquer maintenant sur Blank Logic Apps pour créez un playbook vide, dans le champ Rechercher, tapez Azure Sentinel, puis sélectionnez When a response to an Azure Sentinel alerte is triggered Une fois créé, le nouveau playbook s’affiche dans la liste Playbooks.
Cliquer ensuite sur New Step afin de créer les actions de votre Logic Apps comme par exemple envoyer un mail lorsqu’une alerte est détectée.
Les enums peuvent être vues comme un regroupement de constantes fortement typées. Elles trouvent leur utilité dans de nombreux usages : attribuer une sémantique forte à des valeurs, borner et valider les valeurs possibles d’une donnée, améliorer la lisibilité du code, etc. Leur utilisation peut cependant devenir acrobatique lorsqu’il s’agit de baser des décisions sur leurs valeurs. A mesure que l’enum évolue, chaque endroit où celle-ci a été utilisée en tant que condition doit être revérifié. Si la valeur d’une enum est activement exploitée dans la logique métier, maintenir la base de code dans son ensemble peut devenir un cauchemar : un oubli de vérification peut entraîner une corruption du système dans son ensemble.
N'existe-t-il pas alors un moyen de réduire l'impact des évolutions d'une enum sur le code métier ?
L’approche switch-case
Considérons l’enum AssetClass représentant les différents groupes de matières premières échangeables :
public enum AssetClass {
METAL,
ENERGY,
AGRICULTURAL,
}
Cette enum pourra être utilisée afin de décider des stratégies, mapper, ou tout autre comportement dépendant de la valeur de AssetClass. Imaginons utiliser cette enum pour définir une stratégie de trading automatique à utiliser. Cela ressemblera à quelque chose comme :
public AutomatedTradingStrategy getAutomatedTradingStrategy(AssetClass assetClass) {
switch (assetClass) {
case METAL:return new HedgingStrategy();
case ENERGY: return new SwingTradingStrategy();
case AGRICULTURAL:
default: return DayTradingStrategy();
}
}
Le switch-case est probablement la manière la plus simple et la plus directe de faire. Cela a cependant plusieurs défauts.
La méthode getAutomatedTradingStrategy() retourne un comportement en fonction de la valeur de AssetClass utilisée. Définir un comportement par défaut devient alors obligatoire, même si, dans cet exemple, l’ensemble des valeurs de l’enum sont traitées. Pour cela, nous pouvons soit retourner une implémentation de AutomatedTradingStrategy par défaut, soit retourner null ou alors jeter une exception.
L’utilisation de ce comportement par défaut rendra silencieux l’ajout d’une nouvelle valeur à l’enum. Il faudra alors penser à re-vérifier chaque endroit où AssetClass est impliquée dans des règles métiers. Et rien ne nous protège d'un oubli.
Le problème suivant est probablement le moins évident. L’utilisation du switch-case crée ici un couplage fort entre la logique métier et les valeurs de l’enum brisant ainsi le principe ouvert/fermé : le code doit être ouvert à l’extension mais fermé à la modification. Ici, modifier l’enum implique de modifier chaque bloc de code qui reposait sur ses valeurs. Pourtant, nous n’avons aucun intérêt à savoir si une asset est représentée par une enum, un objet ou autre. Seule sa sémantique compte.
Par exemple, les métaux pourraient être divisés en deux sous-catégories : les métaux précieux et les métaux de base. Tout code reposant sur AssetClass.METAL devra alors être retravaillé afin de prendre en compte ces deux nouvelles valeurs. Le refactoring de l'existant n'apportera aucune nouvelle valeur métier mais exposera un code déjà opérationnel à des risques de régressions.
Le pattern Visitor à la rescousse
Comment pouvons-nous alors briser ce couplage tout en offrant la possibilité de contextualiser la logique métier aux valeurs de l'enum ? La réponse est dans le titre : utilisons le pattern Visitor.
Créons dans un premier temps l’interface qui servira de contrat entre notre enum et le code souhaitant interagir avec.
public interface AssetClassVisitor<T> {
T visitMetal();
T visitEnergy();
T visitAgricultural();
}
L’interface est générique afin que celle-ci puisse permettre des implémentations dont l’objectif diffère selon son contexte d’utilisation.
Il est maintenant nécessaire de modifier l’enum afin que celle-ci accepte toute demande respectant le contrat porté par AssetClassVisitor :
public enum AssetClass {
METAL {
@Override
public <E> E accept(AssetClassVisitor<E> visitor) {
return visitor.visitMetal();
}
},
ENERGY {
@Override
public <E> E accept(AssetClassVisitor<E> visitor) {
return visitor.visitEnergy();
}
},
AGRICULTURAL {
@Override
public <E> E accept(AssetClassVisitor<E> visitor) {
return visitor.visitAgricultural();
}
};
public abstract <E> E accept(AssetClassVisitor<E> visitor);
}
Il ne reste alors plus qu’à l’utiliser. Remplaçons notre switch-case par une implémentation du visitor :
public AutomatedTradingStrategy getAutomatedTradingStrategy(AssetClass assetClass) {
return assetClass.accept(new AssetClassVisitor<AutomatedTradingStrategy>() {
@Override
public AutomatedTradingStrategy visitMetal() {
return new HedgingStrategy();
}
@Override
public AutomatedTradingStrategy visitEnergy() {
return new SwingTradingStrategy();
}
@Override
public AutomatedTradingStrategy visitAgricultural() {
return new DayTradingStrategy();
}
});
}
Comme on peut le constater, chaque valeur de AssetClass porte la responsabilité d’appeler la méthode du visitor appropriée. Il est désormais inutile de connaître les valeurs ou l’implémentation d’AssetClass. AssetClass.AGRICULTURAL pourrait alors être renommé en AssetClass.AGRI sans avoir à modifier quoi que ce soit au niveau de la logique métier. Il est par ailleurs devenu inutile de gérer des comportements par défaut. Les possibilités sont désormais restreintes à celles fournies par l’interface.
Ajoutons une nouvelle asset class
Notre business évolue et nous devons désormais étendre nos activités aux bétails et viandes. Il suffit alors simplement d’ajouter la valeur à notre enum et de mettre à jour notre contrat d’interface.
public enum AssetClass {
METAL {
@Override
public <E> E accept(AssetClassVisitor<E> visitor) {
return visitor.visitMetal();
}
},
ENERGY {
@Override
public <E> E accept(AssetClassVisitor<E> visitor) {
return visitor.visitEnergy();
}
},
AGRICULTURAL {
@Override
public <E> E accept(AssetClassVisitor<E> visitor) {
return visitor.visitAgricultural();
}
},
// La nouvelle valeur
LIVESTOCK_AND_MEAT {
@Override
public <E> E accept(AssetClassVisitor<E> visitor) {
return visitor.visitLiveStockAndMeat();
}
};
public abstract <E> E accept(AssetClassVisitor<E> visitor);
}
public interface AssetClassVisitor<T> {
T visitMetal();
T visitEnergy();
T visitAgricultural();
// La nouvelle méthode
T visitLiveStockAndMeat();
}
Après cela, le code va s’allumer comme un sapin de Noël : plus rien ne compile. Et le compilateur devrait être remercié d’avoir fait un si bon travail ! Toutes ces erreurs mises en évidence de toute part nous montrent que certaines parties du code ne sont pas en mesure de répondre à cette nouvelle valeur. Corrigeons donc cela en utilisant une exception : le trading des bétails et viandes n'est pas automatisable.
public AutomatedTradingStrategy getAutomatedTradingStrategy(AssetClass assetClass) {
return assetClass.accept(new AssetClassVisitor<AutomatedTradingStrategy>() {
@Override
public AutomatedTradingStrategy visitMetal() {
return new HedgingStrategy();
}
@Override
public AutomatedTradingStrategy visitEnergy() {
return new SwingTradingStrategy();
}
@Override
public AutomatedTradingStrategy visitAgricultural() {
return new DayTradingStrategy();
}
@Override
public AutomatedTradingStrategy visitLiveStockAndMeat() {
throw new AutomatedTradingNotSupported("Automated trading for Livestock and meat is not allowed.")
}
});
}
En bref
Lors d’une de mes missions, l'équipe a été confrontée à un nombre conséquent d’enums et de logique métier basée sur leurs valeurs. Le pattern Visitor était notre bouclier contre les cas à la marge au point d'en devenir notre standard dans la gestion des enums.
Utiliser ce pattern n'est pas nécessaire si les enums sont purement descriptives. Cependant, sortir l’artillerie lourde vaut définitivement le coût de développement supplémentaire. Briser le couplage entre la valeur d’une enum et la logique métier offre une souplesse d’évolution supplémentaire tandis que le compilateur réduit la boucle de feedback en mettant en lumière les oublis potentiels.
CSS Grid Layout est un système de mise en forme de pages web bidimensionnel puissant avec des lignes et des colonnes, qui vous aide à faire des mises en page très complexes sans utiliser de flottants ou de positionnement.
Avant de plonger dans le tutoriel, je vous recommande de lire cet article.
Un grand merci à Anthony Rey pour avoir rendu le code CSS plus structuré pour ce tutoriel.
Support du navigateur
Bureau:
Chrome 57
Opera 44
Firefox 52
IE 11 *
Edge 16
Safari 10.1
Mobile / Tablette:
IOS Safari 10.3
Opera Mobile 46
Opera Mini (non pris en charge)
Android 67
Android Chrom 74
Android Firefox 66
Principes de base
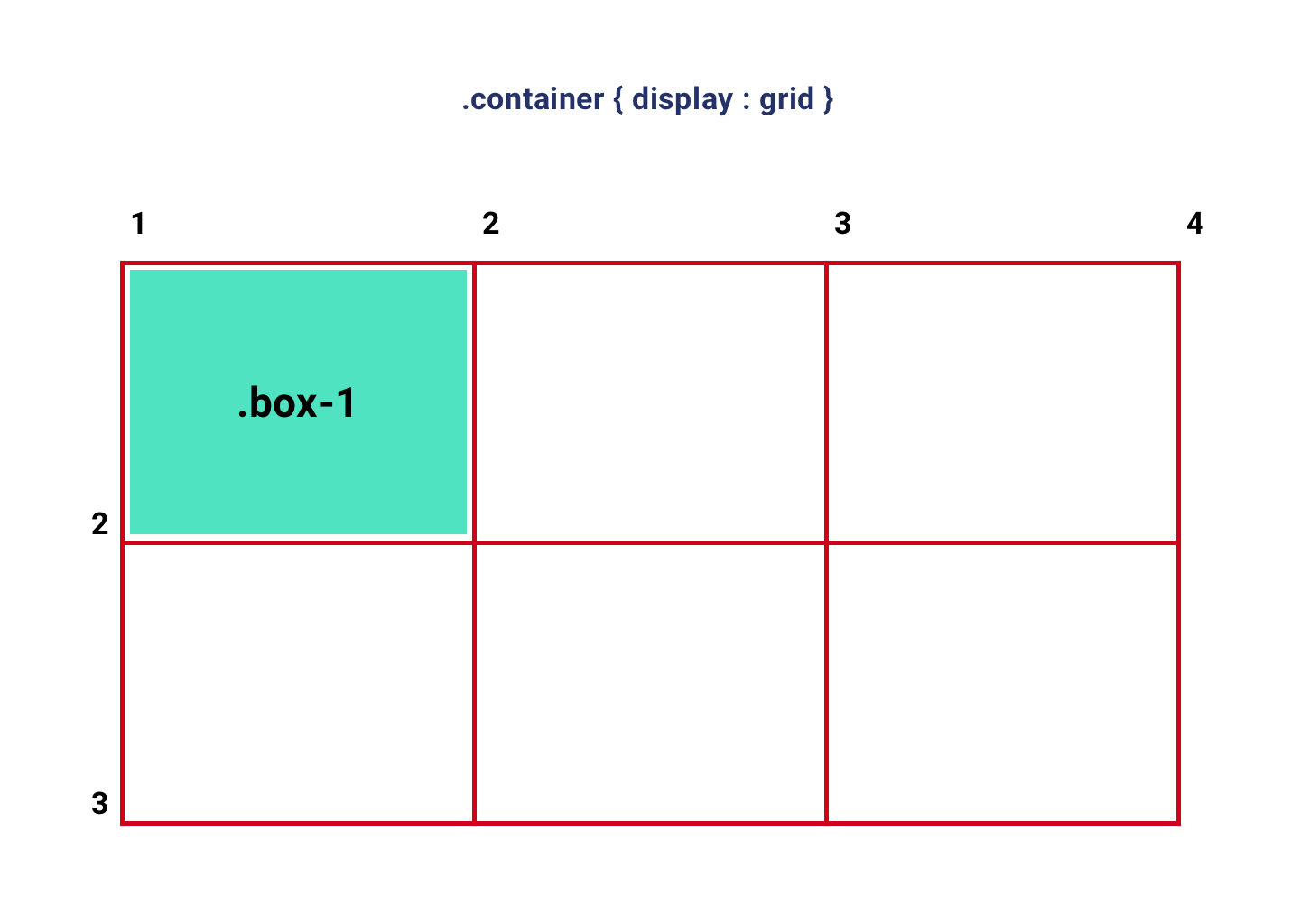
Pour créer une grille, la première chose à faire est de créer un conteneur de grille et définir la propriété display sur grid, puis définir le nombre de colonnes et leur taille à l'aide de la propriété grid-template-columns, enfin définir le nombre de lignes et leur taille à l'aide de la propriété grid-template-rows.
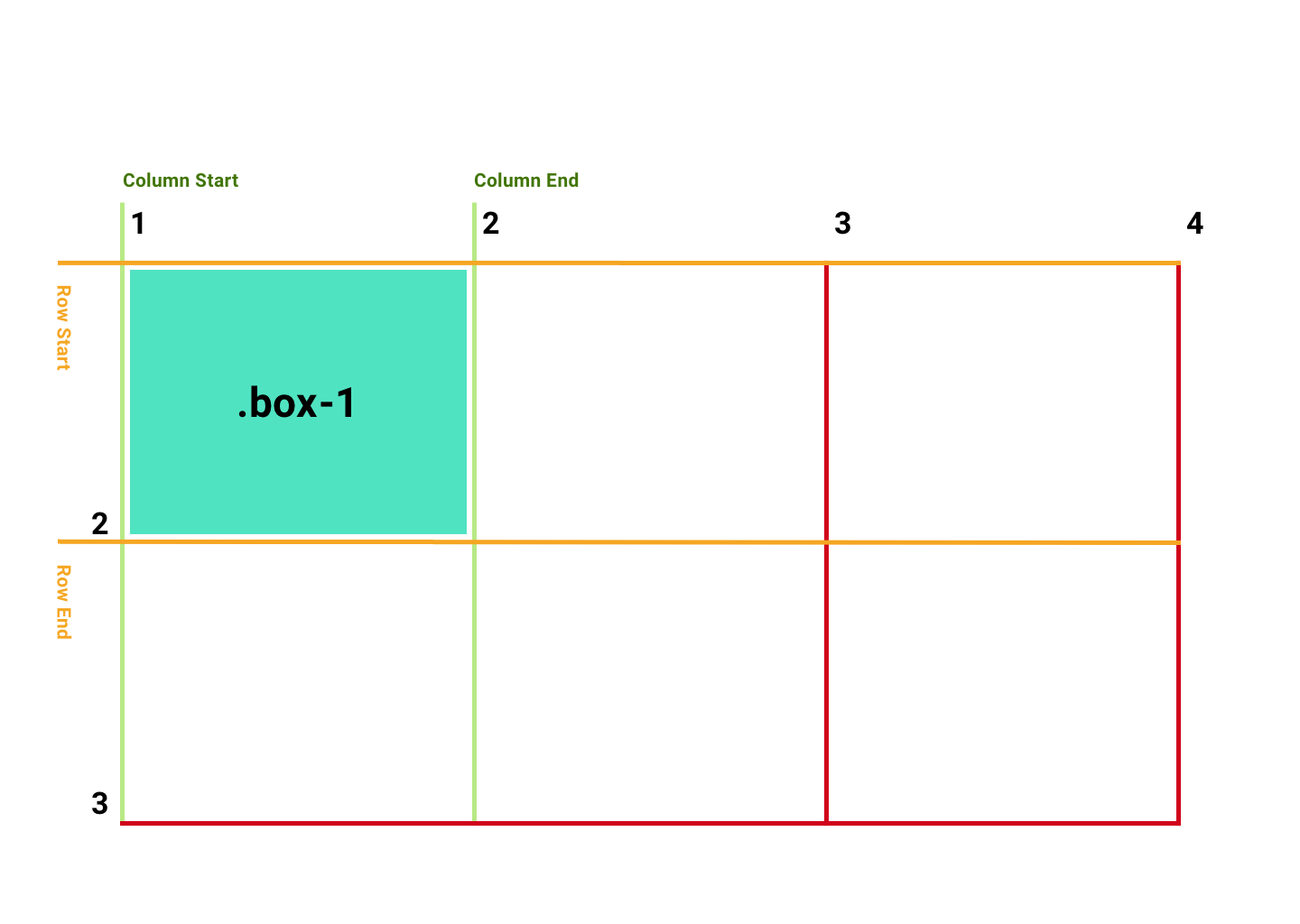
Dans cet exemple, nous avons 3 colonnes et 2 lignes. La largeur de chaque colonne est 1fr, ce qui signifie une fraction de la largeur du conteneur (33,33%). La hauteur pour chaque rangée est 200px.
La colonne de l'élément de grille .box-1 commence entre les lignes de colonne 1 et 2 (lignes vertes) ; la rangée commence entre les lignes de rangée 1 et 2 (lignes orange).
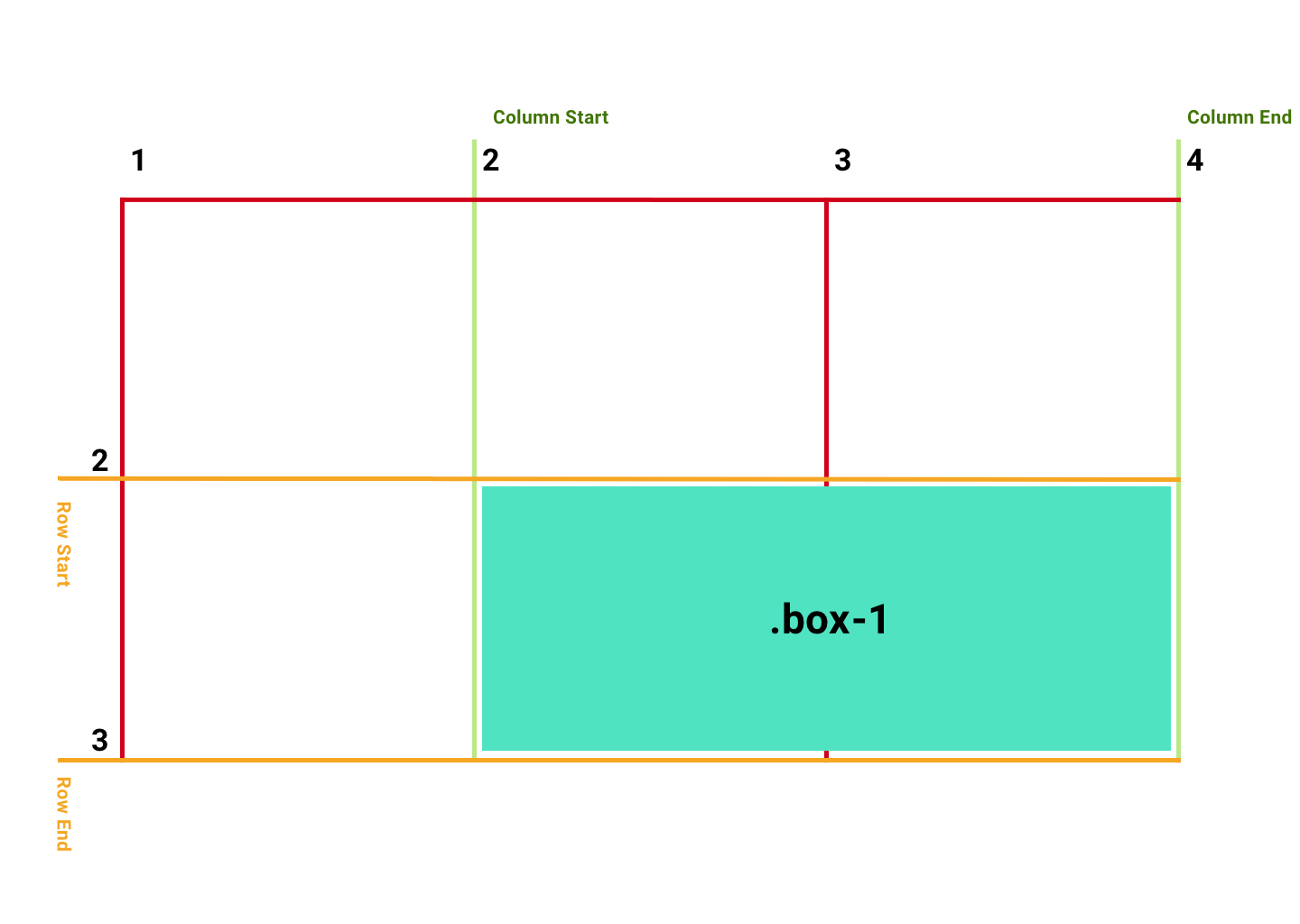
Dans cet exemple, la colonne de la grille commence à la ligne de colonne 2 et se termine à la ligne de colonne 4 (lignes vertes), la rangée débute entre les lignes de rangée 2 et 3 (lignes orange). Avec CSS, vous pouvez placer vos éléments de grille n'importe où dans la grille, et comme pour la Flexbox, l'ordre des éléments de la grille n'a pas d'importance, vous pouvez les réorganiser comme vous le souhaitez.
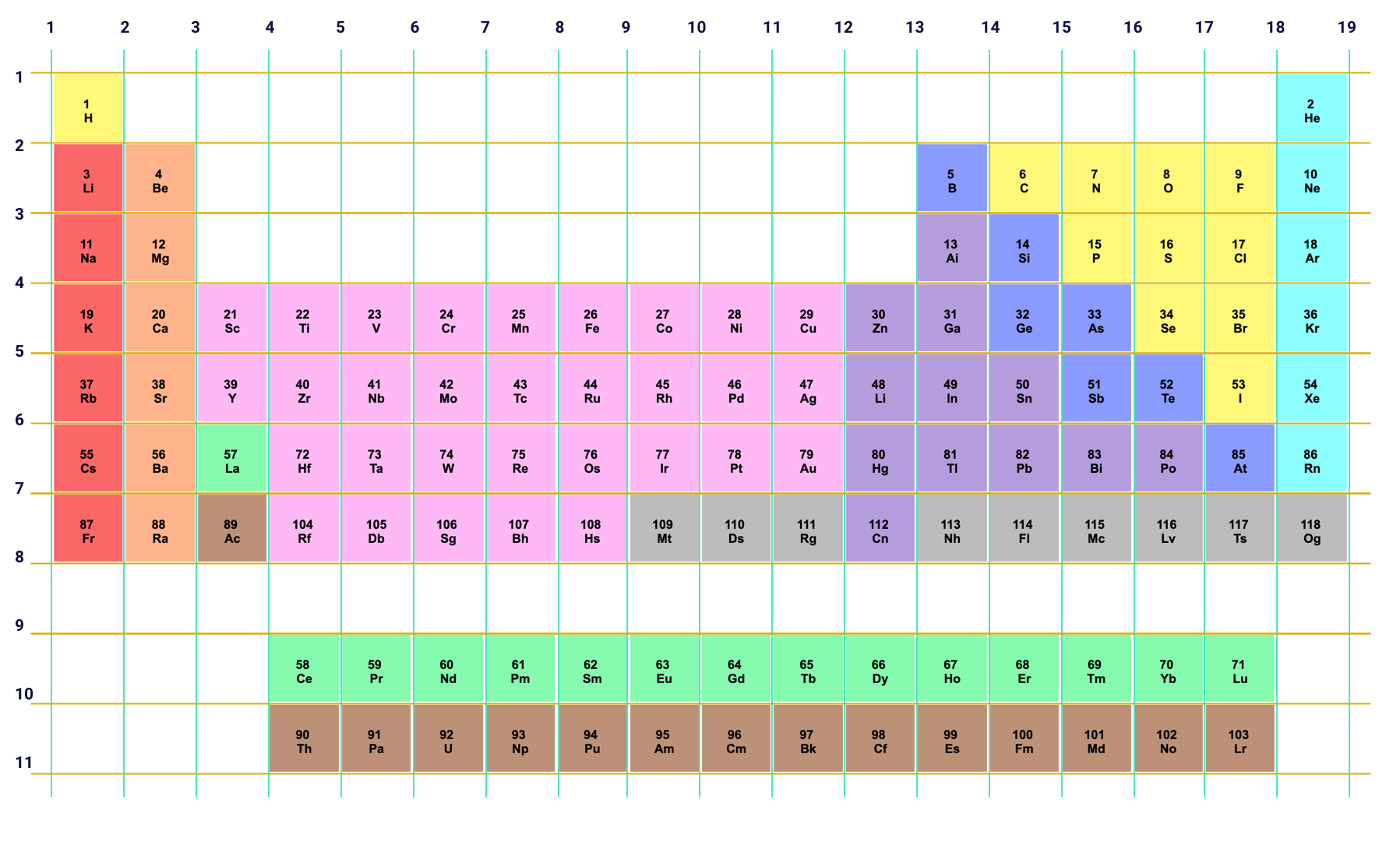
Dans ce tutoriel, nous allons construire le tableau périodique des éléments en utilisant CSS Grid. La grille semble complexe, mais avec l'utilisation de CSS Grid, tout sera facile à prendre en main.
Partie HTML:
Tout d'abord, nous allons créer une div avec une classe .periodic-table, puis nous ajouterons tous les éléments de la grille sur le HTML. La grille contient 118 éléments de grille. Chaque élément possède 3 classes .element.-n (numéro d'élément), une classe du type de l’éléments ainsi qu’une couleur propre pour chaque groupe.
Passons maintenant à la partie CSS. La première chose à faire est de définir la propriété display de la classe .periodic-table en tant que grid, puis de la diviser en 18 colonnes et 10 lignes. Normalement, le tableau périodique ne contient que 9 lignes, mais il y a un espace vide que nous allons considérer comme une ligne vide.
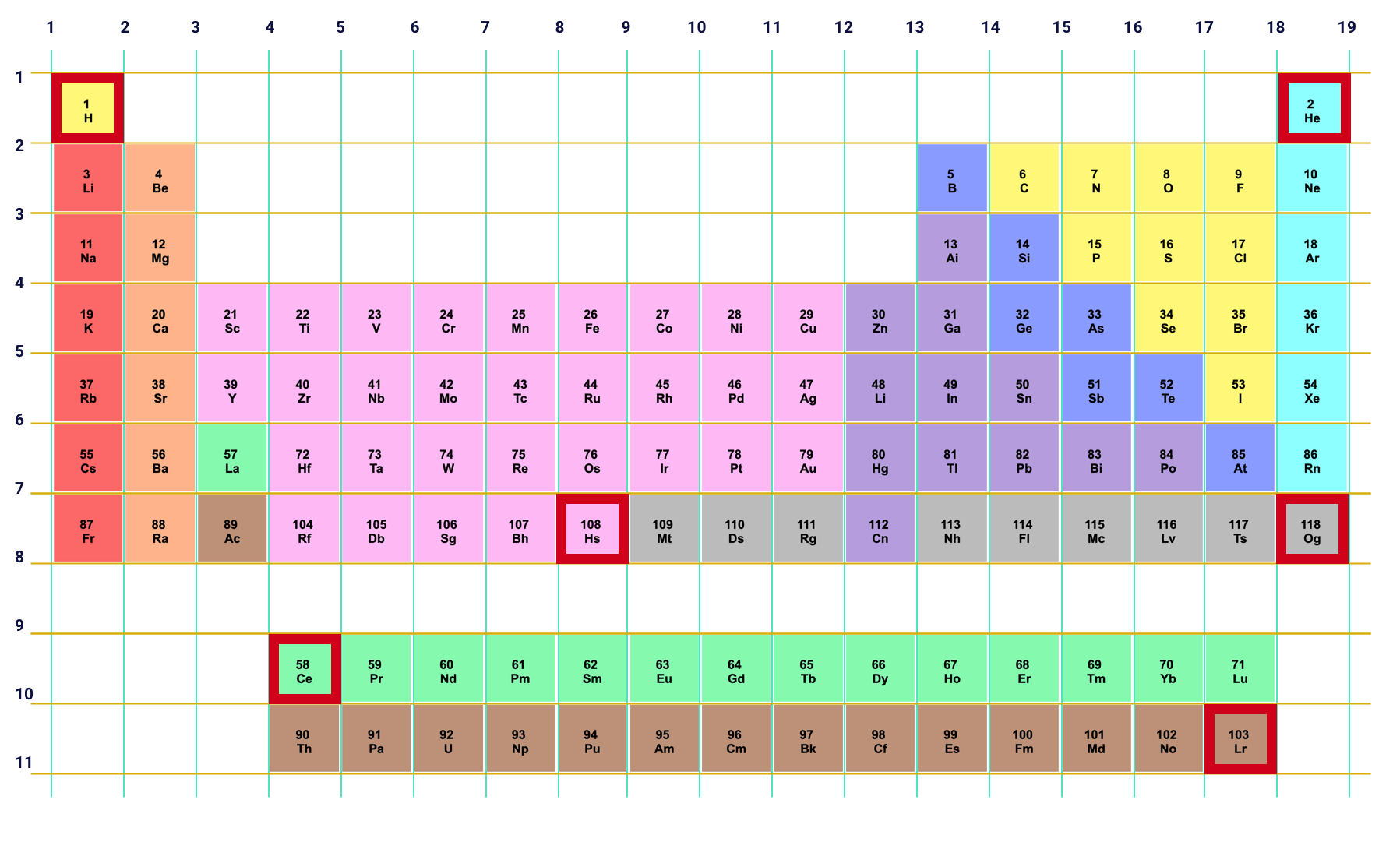
Maintenant, nous allons ajouter le style de chaque élément de la grille, le style comprendra deux propriétés .grid-column et .grid-row . Nous montrerons simplement le style de certains éléments (1, 2, 58, 103, 108, 118) et pas tous les 118 éléments.
CSS Grid est un puissant outil de création de disposition qui vous fera gagner beaucoup de temps, mais je pense que cela sera plus utile pour les dispositions complexes telles que les portefeuilles de mosaïque et les tableaux de bord. Sinon, je pense que Flexbox conviendra mieux pour des projets classiques basés sur une grille comme celle de bootstrap.
Il y a quelques jours j’ai participé à un meetup Evil mob programming : un coding dojo où on peut vraiment être Méchant. J’ai beaucoup aimé cet exercice amusant et enrichissant. Ce retour d’expérience va vous permettre, j’espère, de mieux comprendre le rôle de chacun dans le développement de nouvelles fonctionnalités dans un projet.
Quel était l’exercice ?
Du Mob Programming ?
Je vous invite à lire cet article pour comprendre précisément le concept, ici je ne rentrerai pas dans les détails. Le Mob Programming est une approche du développement où toute l’équipe travaille en même temps sur le même code, au même endroit et sur un unique ordinateur : du Pair Programming à plusieurs.
Le but de cet exercice est d’arriver à produire quelque chose tous ensemble et de permettre à tous de participer activement au développement.
Différents rôles
Trois rôles sont utilisés dans cette pratique. Comme pour le Pair Programming, on retrouve un “Driver” et un “Navigator” :
Le “Navigator” est là pour donner la route à suivre pour arriver à une nouvelle fonctionnalité ou au terme de l’exercice dans le cas de notre kata. C’est lui qui communique avec le “Driver” pour lui donner la prochaine étape à effectuer et le code qu’il va devoir produire.
Le “Driver” implémente ce que le “Navigator” explique à l’oral. Tout le code qu’il produit vient du “Navigator”, c’est, pour résumer, l’interprète entre l’homme et l’ordinateur.
Le reste de l’équipe participe activement en donnant son point de vue sur les choix du “Navigator”. Elle ne communique pas directement avec le “Driver” pour garder un environnement productif.
Tout le monde y passe
Chacun, à tour de rôle, va pouvoir passer au clavier pour être le “Driver” ou avoir le rôle de “Navigator”.
Dans notre cas, nous étions très nombreux (une quinzaine de “mobeurs”), nous changions de place toutes les 4 minutes. C’était un peu court à mon goût, je pense que des rotations toutes les 8 à 10 minutes sont plus pertinentes si on fait l’exercice sur un plus gros laps de temps.
Mode “Evil” ?
Avant de démarrer l’exercice, nous avons tiré une carte pour savoir si nous allions avoir le rôle de “Méchant” ou de “Gentil”. Les “Gentils” ont un comportement bienveillant, ils tentent de faire avancer la session. Les “Méchants”, en revanche, doivent essayer de la saboter sans que personne ne s'en rende compte.
Nous sommes appelés à reprendre le travail d’un collègue qui a travaillé pour une société de Tennis. Le contrat signé avec le client est de 10h et notre collègue n’a travaillé que 8h30 sur le projet. Notre commercial nous demande de reprendre le projet pour le temps restant. Quand on découvre le code, tous les tests passent et le travail est terminé (le service est rendu). Nous devons profiter du temps qu’il nous reste pour retravailler le code existant pour le rendre plus lisible et pour pouvoir faire un retour à notre collègue sur sa façon de coder.
Comment s’est passé la session ?
Premières minutes de découverte
Nous avons pris le temps au début de l’exercice de parcourir le code écrit par notre collègue pour comprendre ce qu’il a implémenté. Les tests étaient déjà présents, ils nous ont aidé à comprendre que le but est de donner le score en anglais en fonction du nombre de points marqué par les deux joueurs de tennis.
Par exemple si le joueur “A” a marqué deux fois et le joueur “B” a marqué trois fois, le score est de 30-40. Le programme doit alors nous donner “Thirty-Forty”. En cas d’égalité, le score s’énonce de cette manière : Fifteen-All pour un 15-15. En cas d’avantage ou de fin de set, le score est “Advantage A” pour le score : Adv-40 et “Win for A” si le joueur “A” remporte le set.
On s’est assuré que les règles étaient bien comprises par tous avant de se lancer dans le refacto.
Les tests existants ne sont pas forcément d'une grande qualité, nous aurions pu commencer par les modifier mais nous avons préféré nous attaquer à l’implémentation.
À l’attaque du code
Maintenant que tout le monde est au point, il est temps de commencer. Les “Méchants” peuvent commencer à s’amuser en tentant de saboter le travail de l’équipe.
Exemple de sabotage
Pour cet exercice, j’ai eu la chance d’avoir le rôle de “Méchant”. Il est assez simple (et surtout bien amusant) de ralentir le travail de l’équipe. Je vous donne quelques exemples de sabotage avec une comparaison dans la vie réelle.
⟩ Interférer avec le “Navigator”
Pour rappel, c’est uniquement le “Navigator” qui donne la route à suivre pour mener le développement. Il est possible de rendre son rôle pénible : parler plus fort que lui, parler à sa place au “Driver”, enlever la concentration du groupe avec des blagues, des trolls, …
Comparable à :
un collègue qui pose des questions qui n’ont rien à voir avec le sujet,
un téléphone qui sonne en plein milieu de la session,
“Jo l’rigolo” avec ses blagues de Kaamelott.
⟩ Se lancer dans un refacto compliqué
Tout le monde n’a pas la même logique et ne code pas de la même manière, il est donc facile d’imposer un choix qui peut paraître simple mais qui finalement ne mène à rien. Cela fait perdre du temps et peut donner un sentiment de frustration aux autres membres de l’équipe.
Comparable à :
quelqu’un qui veut mettre en pratique la dernière nouveauté du langage de programmation sans même l’avoir comprise,
partir dans un développement sans s’assurer que les autres comprennent ce que l’on fait.
⟩ Ne pas écouter le reste de l’équipe
Quand on est “Driver” ou “Navigator”, on a une plus grande responsabilité. Il faut donc faire au mieux pour que ce qu’on fait soit compris de tous. Si on n’écoute pas les autres, on peut facilement nuire au travail de l’équipe. Par exemple, un “Driver” qui n’en fait qu’à sa tête peut détruire tout le travail d’un autre ou rendre le code parfaitement incompréhensible.
Comparable à :
un développeur qui n’en fait qu’à sa tête et ne veut pas écouter le point de vue des autres,
l’équipe qui n’écoute pas ceux qui connaissent le métier.
Ce qui fait avancer le développement
Certains avait le rôle de “Gentils” et devaient, malgré les embûches des “Méchants”, faire avancer le développement. Voici ce qui permet le bon avancement de la fonctionnalité.
⟩ Des experts métiers
Certaines personnes connaissaient déjà le kata et ont pu facilement donner une direction à suivre pour arriver au bout du développement. Si on compare avec le monde réel, il est important de faire participer un expert métier qui connaît parfaitement ce qui est attendu. Même s’il ne sait pas coder, il sera bien utile pour produire un code compréhensible.
Il est important de toujours garder contact avec les experts métier qui savent ce qu’il faut au final.
⟩ De l’écoute
Un “Gentil” veillait particulièrement à ce que les rôles soient respectés : seul le “Navigator” échange avec le “Driver”. Il recentrait également les personnes sur une unique tâche, pour ne pas avoir plusieurs conversations en même temps.
Il faut apprendre à mettre son orgueil de côté, tout le monde peut avoir une bonne idée et doit avoir la chance de s’exprimer.
⟩ De la bienveillance
Il y avait tout type de profil dans l’assistance. Il faut veiller à ne pas rabaisser les autres mobeurs et adopter une communication non violente. Cela fait progresser tout le monde et fait grandir l’équipe plus rapidement.
Conclusion
Ce Mob Programming n’était qu’un exercice, un jeu pour mieux comprendre comment fonctionne une équipe. Avant de mettre en place ce type d’approche, il faut se demander si c’est pertinent et ce que ça va apporter. Plusieurs essais peuvent être nécessaires avant de trouver la bonne configuration : nombre de personnes présentes, durée des rotations, …
Je me suis bien amusé lors de cette session, je vous encourage à organiser ou participer à ce type d’événement qui permet de faire à la fois du team building et découvrir une nouvelle façon de coder à plusieurs. En plus, si on peut être un “Méchant”, on y prend encore plus de plaisir. 😈
L’injection de dépendances (DI) est un pattern dans lequel vous laissez une tierce partie (ie, un framework) fournir les implémentations. Cela présente de grands avantages :
réduction du couplage dans vos apps
facilitation du testing
cela force une meilleure organisation et structuration du code, en éliminant du boilerplate et en créant une couche DI
Il n’y a pas de méthode officielle pour implémenter ce pattern sur Android. Pourtant, Google tend à favoriser un de leur frameworks : Dagger. Malgré une grande versatilité et une grande efficience, la courbe d’apprentissage de cet outil est plutôt élevée. De plus, il requiert la création de nombreux fichiers, même pour un petit projet.
Le but de cet article est de vous présenter un plus petit, plus simple mais puissant framework de DI : Koin. On ira plus loin en faisant le refactoring d’un projet Android développé avec :
Plusieurs Android Architecture Components
Dagger 2
Le projet
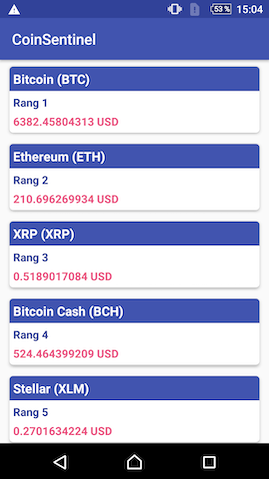
Coinsentinel est une application Android hébergée sur GitHub ici. Elle affiche la valeur courante et le rang des principales cryptomonnaies. Pour avoir des informations à jour, elle interroge l’API libre d’accès de coinmarket. Elle fonctionne aussi hors ligne pour assurer une expérience utilisateur optimale, peu importe si elle a un accès internet ou non. L’interface est simple : c’est une liste triée de cryptomonnaies. Un swipe haut-bas déclenche une tentative de rafraîchissement des données.
Voici à quoi elle ressemble :
Dagger
On utilise Dagger pour injecter :
Une instance de Gson instance, pour désérialiser les réponses http
Un deserializer métier, qui map le JSON vers un POKO (Plain Old Kotlin Object)
Une représentation de notre base de données SQLite
L’unique DAO utilisé dans cette base de code
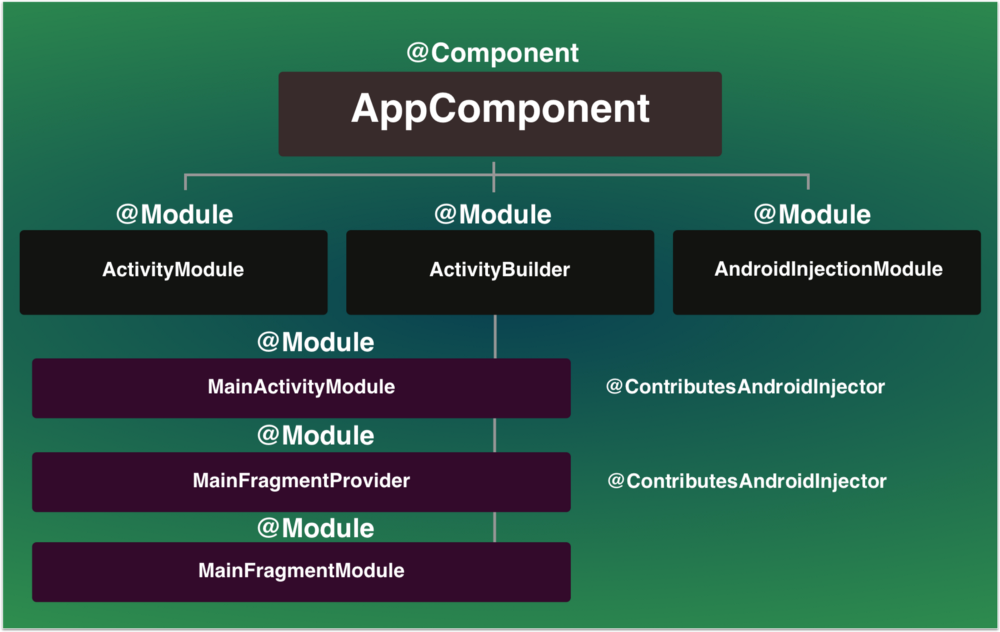
Avant d’aller plus loin, regardons de plus près comment Dagger construit son arbre de dépendances :
Comme vous l’avez peut-être déjà deviné, l’arbre est construit en déclarant des composants et des modules. Typiquement, un composant est composé de plusieurs modules. Comme la documentation l’indique : “Dagger n’utilise pas de réflection ni de génération de code au runtime, mais fait son analyse à la compilation, et génère du code source Java.”. Cela signifie que vous allez avoir beaucoup de fichiers qui seront générés lors de la compilation, dans le but de générer le graph de dépendances. Cela est supposé permettre au build de passer à l’échelle lorsque l’application grossit MAIS, cela se fait au prix d’un certain overhead, même pour de petites applications.
Bien qu’étant plutôt simple, Coinsentinel a 3 fichiers qui sont uniquement dédiés à la DI :
AppComponent.kt
AppModule.kt
MainActivityModule.kt
Je pense que la syntaxe de Dagger n’est pas parfaite dans une app native Kotlin (utilisation d’annotations là où en Kotlin on utilisera plutôt des DSL par exemple). C’est tout simplement parce que ce framework est écrit en Java. Pour résumer, Dagger est très versatile, mais nous forme à beaucoup développer même si le projet est petit. Cela donne l’impression de faire de l’over-engineering.
C’est là qu’intervient Koin. C’est “un framework de DI léger et pragmatique pour Kotlin https://insert-koin.io/”. En bonus : il est 100% “Écrit en pur Kotlin, en utilisant seulement de la résolution fonctionnelle : pas de proxy, pas de génération de code, pas de réflexion.”.
En fait, c’est “juste” un DSL qui fournit une syntaxe agréable et concise. Bien sûr, cela contribue à développer dans les règles de l’art de Kotlin. L’outil s’intègre aussi vraiment bien avec les Android Architecture components et les librairies AndroidX.
Refactoring
Etape 0 : Mise à jour de la version de androidX appcompat
Cette nouvelle version fait qu’AppCompatActivity implémente l’interface LifecycleOwner. Celle-ci est nécessaire quand on développe avec les architecture components.
Étape 1 : dépendances gradle de Koin
Nous allons utiliser Koin 2. Cette dernière version qui vient de sortir est riche en fonctionnalités et activement maintenue. Dans app/build.gradle, ajoutez les lignes suivantes pour importer Koin :
// Koin
def koin_version = '2.0.1'
// Koin for Kotlin
implementation "org.koin:koin-core:$koin_version"
// Koin for Unit tests
testImplementation "org.koin:koin-test:$koin_version"
// AndroidX (based on koin-android)
// Koin AndroidX Scope feature
implementation "org.koin:koin-androidx-scope:$koin_version"
// Koin AndroidX ViewModel feature
implementation "org.koin:koin-androidx-viewmodel:$koin_version"
Maintenant vous avez tout ce qu’il vous faut pour utiliser Koin.
Étape 2 : Refactoring du package DI
Tout d’abord, supprimez AppComponent et MainActivityModule puisque nous allons factoriser le code de AppModule. Puis, remplacez le code de AppModule par :
package fr.ippon.androidaacsample.coinsentinel.di
import androidx.room.Room
import com.google.gson.GsonBuilder
import fr.ippon.androidaacsample.coinsentinel.api.CoinResultDeserializer
import fr.ippon.androidaacsample.coinsentinel.api.CoinTypeAdapter
import fr.ippon.androidaacsample.coinsentinel.db.AppDatabase
import fr.ippon.androidaacsample.coinsentinel.db.Coin
import org.koin.dsl.module
import java.lang.reflect.Modifier
private const val DATABASE_NAME = "COIN_DB"
val appModule = module {
single {
GsonBuilder()
.excludeFieldsWithModifiers(Modifier.TRANSIENT, Modifier.STATIC)
.serializeNulls()
.registerTypeAdapter(Coin::class.java, CoinTypeAdapter())
.excludeFieldsWithoutExposeAnnotation()
.create()
}
single { CoinResultDeserializer(get()) }
single {
Room.databaseBuilder(get(), AppDatabase::class.java, DATABASE_NAME)
.build()
}
single {
get<AppDatabase>().coinDao()
}
single { CoinRepository(get(), get()) }
viewModel { CoinViewModel(get()) }
}
Ici :
Nous déclarons un unique module appModule qui est en read only
Nous remplaçons les méthodes annotées avec @Singleton par les déclarations Kotlin DSL équivalentes single.
Le get() résout la dépendance d’un composant. Nous pouvons aussi l’utiliser pour récupérer la dépendance et appeler une méthode sur celle-ci, comme nous l’avons fait pour get().coinDao()
Nous avons ajouté CoinRepository à la définition du module, puisqu’il était précédemment injecté
Koin embarque une notation viewModel pour définir notre ViewModel. Comme vous pouvez vous en douter, cette librairie simplifie l’utilisation de cet architecture component. Nous verrons pourquoi dans une prochaine section.
Ici encore, c’est assez rapide : nous enlevons le boilerplate et le remplaçons avec une simple déclaration Kotlin DSL. Dans CoinSentinelApp, supprimez la variable dispatching android injector :
@Inject
lateinit var dispatchingAndroidActivityInjector: DispatchingAndroidInjector<Activity>
Ensuite, supprimez l’implémentation de l’interface HasActivityInjector :
class CoinSentinelApp : Application(), HasActivityInjector {
Supprimez aussi la fonction qui lui est liée :
override fun activityInjector(): DispatchingAndroidInjector<Activity> {
return dispatchingAndroidActivityInjector
}
Finalement, dans onCreate, changez l’initialisation de la DI initialization en remplaçant :
C’est aussi possible de configurer des loggers, des android contexts, des propriétés etc. Plus de documentatoon ici.
Étape 4 : Refactoring du ViewModel et du Repository
Dans cette étape rapide, vous avez juste à supprimez les annotations @Singleton et @Inject dans les fichiers CoinViewModel et CoinRepository.
Étape 5 : Refactoring de la MainActivity
Dernière étape du refactoring. Remplacez dans la MainActivity
@Inject
lateinit var coinViewModel: CoinViewModel
par
private val coinViewModel: CoinViewModel by viewModel()
Vous devez aussi supprimer la référence à AndroidInjection dans onCreate() :
AndroidInjection.inject(this)
Et… c’est fini. Vous pouvez voir une notation intéressante : by viewModel(). C’est un mot clé DSL qui permet d’injecter une instance de ViewModel (déclarée dans notre module). Si ce ViewModel a besoin d’être partagé entre plusieurs composants, utilisez juste à la place by sharedViewModel().
De la même manière, si nous avions voulu injecter le serializer ou le repository, nous aurions utilisé by inject(). Pour plus d’explications, je vous invite à consulter la documentation.
Il y a un autre avantage à utiliser Koin : on n’a plus besoin d’utiliser les déclarations lateinit var. À la place, on peut déclarer des private val. Cela veut dire que nos variables injectées :
sont readonly (var vers val)
ont une meilleure visibilité, plus liée à leur contexte (private)
ne vont pas causer de lateinit exceptions. Le mot clé lateinit indique au compilateur que la variable va être nulle à son initialisation, mais ne le sera plus une fois qu’on tentera d’y accéder. Si on y accède alors qu’elle n’est pas initialisée, on obtient une exception runtime de ce genre :
kotlin.UninitializedPropertyAccessException: lateinit property X has not been initialized
C’est vraiment douloureux à débugger dans un contexte Android. Avec Dagger, on a eu plusieurs problèmes pendant du “monkey testing”, i.e., taper partout dans l’application. En interne, ce genre de tests créait intensivement des fragments. Parfois, de manière imprédictible, les variables n’étaient pas injectées suffisamment tôt, ce qui faisait tomber l’application.
[Non reliée à Dagger ni à Koin]
C’est aussi pourquoi, si vous regardez le refactoring sur GitHub, vous verrez qu’une autre variable a été changée. J’ai enlevé l’initialisation de coinAdapter de la fonction init(). À la place, la variable est initialisée by lazy :
De
private lateinit var coinAdapter: CoinAdapter
vers
private val coinAdapter: CoinAdapter by lazy {
CoinAdapter(coins, this)
}
L’initialisation by lazy indique que l’objet va être créé quand coinAdapter sera accédé pour la première fois. Grâce à cela :
nous pouvons utiliser val à la place de var
c’est plus efficace puisqu’aucune mémoire ne sera consommée tant que nous n’utilisons pas coinAdapter.
Conclusion
Koin est vraiment une librairie géniale à utiliser. Elle simplifie beaucoup la gestion des dépendances et offre de nombreuses fonctionnalités. D’ailleurs, certaines sont dédiées à Android et aux architecture components, pour vous aider d’autant plus dans votre développement. J’ai volontairement omis de parler de certains de ses concepts comme les scopes, ou son utilisation dans le framework web officiel de JetBrain’s, Ktor. C’est pour ça que je vous recommande de consulter le repo github officiel et le site (plus bas dans les sources).
Qu’est ce qu’un moteur de recherche ? Vous me répondrez, certainement, un moteur qui permet de chercher des choses. Mais quelles sont ces choses ? Des mots ? Des phrases ? Un contexte ? Quelle est la limite pour notre moteur de recherche ? Cette nuance est essentielle et se doit d’être testée.
Dans Elasticsearch, nous disposons d’un outil, les analyzers. Ils sont le coeur de notre moteur. Une fois configurés comme on le souhaite, ils redéfinissent la façon qu’aura le moteur d'interpréter les données. Ils permettent de découper un texte en différents tokens qui seront utilisés pour la recherche.
Nous verrons comment travailler les analyzers et SURTOUT comment les tester. Difficile de ne pas être sûr de comment notre moteur va chercher les éléments demandés.
Cet article s’adresse à des personnes ayant déjà manipulé Elasticsearch et qui souhaitent travailler la pertinence de celui-ci à travers les analyzers.
À la fin de l’article, vous saurez réaliser/tester des analyzers via Testcontainers. De plus, un Github est à votre disposition si vous souhaitez tester ou utiliser une partie du code. Voici le lien : https://github.com/contejulie/analyzer-test
Important : la première fois que vous lancerez les tests, cela vous prendra un peu de temps. Ce temps correspond notamment au téléchargement de l’image Elasticsearch nécessaire. De plus, il vous faudra obligatoirement Docker d’installé sur votre ordinateur.
Pourquoi ai-je écrit cet article ?
Dans le cadre d’un projet, le besoin du client était de réaliser plusieurs analyzers permettant de modifier l’indexation et la façon de rechercher les différentes données. Cet article abordera différents types de filtre comme un filtre de caractères au travers d’une regex et une élision.
Les technologies
Les technologies qui interviennent dans cet article sont Elasticsearch en version 7.2.0 (la plus récente lors de l’écriture de l’article), Java 1.8, Testcontainers, Maven et Docker. Il vous faudra impérativement Docker (testé en version 18.09.2) pour pouvoir effectuer des tests avec Testcontainers.
Définitions
Analyzer : C’est le coeur de notre moteur de recherche. Il est composé de divers filtres/séparateurs qui va permettre de travailler les données en amont de l’indexation et de la recherche. Il est constitué de tokenizers et de filtres. Cela permet de compartimenter un texte en phrase ou mots ou contexte et bien d’autres. Les compartiment créé sont appelés Tokens. Par exemple “tacos de Lyon” devient “tacos” “de” “lyon” sans aucun filtre.
Token : Élément qui résulte du découpage effectué par l’analyzer. C’est cet élément qui sera utilisé lors de la recherche. Par exemple, un texte “le 4” aura deux tokens tels que “le” et “4”.
Un analyzer possède une certaine anatomie qu’il convient de respecter. Il est constitué de :
Char_filter permettant de filtrer les caractères via une regex pour le pattern replace par exemple.
Tokenizer indiquant comment séparer les différents tokens. On peut utiliser le séparateur “-” où “amuse-bouche” deviendra “amuse” et “bouche”. Dans un autre cas, un espace servira de séparateur.
Token filters permet de modifier, ajouter, supprimer les tokens résultant de l’analyse d’un texte.
Un peu de vocabulaire : qu’est ce qu’une élision ? Une élision correspond à l’effacement d’une voyelle en fin de mot. Lors d’une élision, “le avion” devient “l’avion” par exemple.
Comment ça marche ?
Création du POM
Voici les différentes choses dont nous avons besoin pour arriver à tester nos analyzers :
Il faut intégrer le elasticsearch-rest-high-level-client qui sera utilisé pour développer, en Java, la configuration et la communication avec Elasticsearch au niveau du client fourni.
Testcontainers va nous permettre de faire des tests d’intégration facilement en déployant de lui-même un dockerfile. Par ailleurs, il gère aussi le cycle de vie du container qu’il a lancé.
Enfin, Assertj est là pour faire nos assertions.
Testcontainers
Rentrons dans le coeur de notre sujet Testcontainers. Testcontainers est une librairie Java qui va nous permettre lancer divers containers comme une base de données ou autre. Ici, elle nous servira à lancer notre Elasticsearch sur lequel nous souhaitons faire des tests.
Dans ce fichier, nous avons la description de deux analyzers. Le premier analyzer ne contient rien si ce n’est le tokenizer standard. Il est là pour faire la comparaison avec le second.
Le second “default” décrit l’analyzer appliqué par défaut sur tous les champs. Il utilise le même tokenizer que le premier mais utilise différents filtres en plus . Il est composé d’un char_filter qui va permettre d’enlever tous les chiffres dans le texte analysé. Il utilise le tokenizer “standard”. Tous les mots seront séparés par un caractère spécial. Par exemple, “amuse-bouche” deviendra “amuse” et “bouche”. Il utilise les filtres lowercase (tous les textes seront analysés en minuscule) et french_elision. french_elision permet d’enlever toutes les élisions référencées. Nous ne renseignons que L et d pour l’exemple. Une phrase “je monte dans l’avion” sera coupée en différents tokens qui sont “je” “monte” “dans” “avion”. Le l’ de “l’avion” a été retiré.
Les dernières configurations
Tout d’abord, nous devons créer un index avec nos settings dans notre Elasticsearch.
static void createIndex() throws IOException {
try (CloseableHttpClient httpclient = HttpClients.createDefault()) {
HttpPut putAction = new HttpPut(getBaseUrlElasticsearch());
putAction.setEntity(new InputStreamEntity(resolveSettingsDefinitionStream(), ContentType.APPLICATION_JSON));
ResponseHandler<String> responseHandler = response -> {
int status = response.getStatusLine().getStatusCode();
HttpEntity entity = response.getEntity();
System.out.println(EntityUtils.toString(entity));
if (status < 200 || status >= 300) {
throw new RuntimeException("Unexpected response status: " + status);
}
return "";
};
httpclient.execute(putAction, responseHandler);
}
}
Le but de cette méthode est simple. Effectuer une requête Elasticsearch en intégrant les settings déclarés au dessus. Pour cela :
Création d’une requête HTTP PUT qui va permettre de créer et mettre à jour l’index en récupérant l’URL configurée avant.
Il faut donner les settings en paramètre de la requête en lui indiquant le chemin du fichier.
Il faut effectuer la requête en s’assurant que tout s’est bien passé.
Les tests
Le fichier de test pour réaliser les tests d’intégration Elasticsearch.
@Before
public void setup() throws IOException {
TestUtils.startElasticsearch();
TestUtils.createIndex();
}
Il faut commencer par appeler les fonctions décrites plus haut qui nous permettent de lancer un container Elasticsearch et de créer l’index et ses settings.
Nous aurons plusieurs tests qui intégreront la même logique. Il faudra donc créer une méthode qui reprendra le coeur des différents tests.
Cette méthode prend en entrée le texte à analyser, le texte attendu à l’analyse et le nom de l’anayzer. Elasticsearch met à disposition une API permettant de comprendre efficacement comment est analysé le texte avec l’analyzer stipulé. On crée un objet JSON qui aura:
Une propriété “analyzer” servant à indiquer l’analyzer utilisé.
Une propriété “text” qui sera analysé.
Ensuite, il faut effectuer la requête et récupérer les tokens retournés par Elasticsearch. Et pour finir, il est nécessaire de comparer les divers tokens retournés et ceux que nous souhaitions en sortie.
Pour finir, voici un exemple de test réalisé :
@Test
public void testAnalyzerWithFilters() {
String analyzer = "default";
Map<String, String[]> cases = new HashMap<>();
cases.put("confiture d'abricot", new String[]{"confiture", "abricot"});
cases.put("chaussure 1999 6kg", new String[]{"chaussure", "kg"});
cases.forEach((textToAnalyse, expectedTokens) -> analyzerTestWithInputAndAnalyzer(textToAnalyse, expectedTokens, analyzer));
}
Il conviendra d’utiliser l’analyzer default et de décrire les cas souhaités dans une map. Avec le filtre french_elision, “confiture d’abricot” sera découpé en deux tokens tels que “confiture” et “abricot”.
Conclusion
Je vous ai décrit une base générale de test d’intégration sur les analyzers. Vous pourrez la personnaliser selon vos use case. Il existe encore beaucoup d’autres filtres tel qu’un stemmer pour la langue de votre choix et bien d’autres encore que je vous laisse découvrir à travers la documentation.
Maintenant, vous savez faire des analyzers et vous savez les tester !
En intervenant sur différents projets Spark (parfois en mode “pompier”) et en recueillant les témoignages de mes collègues, j’ai constaté que les principales causes d'échec sont :
le faible niveau de compréhension du fonctionnement de cet outil et des contraintes de traitement distribué,
le manque d’industrialisation et de bonnes pratiques (Tests automatisés, CI/CD, Workflow Git, Code Review, etc.).
Dans certains cas, les projets sont au point mort (rien ne marche, le budget est consommé). Dans d’autres, les défauts du code sont compensés par des clusters surdimensionnés. Dans les deux cas, les pertes financières sont considérables.
La migration vers le Cloud n’arrange pas les choses. En mode pay-as-you-go, moins vos applications sont performantes, plus vous payez pour les faire tourner. Le facteur 10 (et même plus) sur le coût du cluster, par rapport à ce que consommerait une application bien optimisée, ne m’étonne plus du tout. Dans ce cas, il est plus pertinent de parler d’efficience que simplement des performances.
Le fait de négliger les aspects de l’industrialisation génère un coût important pour tout projet de développement informatique. Cet effet est encore plus accentué pour un projet Spark à cause d’une surconsommation de ressources de calcul (coût du cluster).
Solutions
Formez les développeurs
Je vois souvent des équipes composées de développeurs venant de tous horizons et qui se sont retrouvés à faire du Spark sans y être formés. À mon avis, cela arrive parce que Spark est connu pour être simple à utiliser, ce qui est tout-à-fait vrai, surtout si on le compare à Hadoop MapReduce. Quelqu’un qui ne maîtrise que le SQL peut créer et exécuter un job Spark.
En revanche, développer une application performante et robuste est une toute autre histoire. Il ne suffit pas de savoir se servir des APIs Spark. Il est indispensable de comprendre ce qu’il se passe sous le capot et d’avoir un bon niveau de culture de l’univers du calcul distribué.
Une autre raison est probablement d’ordre financier. Les formations sont chères. On préfère ainsi laisser les développeurs monter en compétences au cours du projet en apprenant de leurs propres erreurs. Avez-vous calculé combien peut vous coûter ce mode d'apprentissage ?
Pour vous en donner une idée, voici ses possibles conséquences :
surconsommation des ressources,
faible productivité de l’équipe,
retard du projet,
démotivation de l’équipe,
abandon du projet.
Donnez les moyens pour monter en compétence
Spark est un outil très en vogue. ll existe donc une multitude de livres, d’articles de blog et d’exemples de code sur Stack Overflow. Le problème est que toutes ces sources d’information ne se valent pas. Certaines sont dépassées, d’autres sont difficiles à lire. Il y a même des livres qui contiennent de fausses affirmations.
Ayant lu (ou entamé) plusieurs livres sur Spark, je conseille vivement de privilégier le livre “Spark: The Definitive Guide” de O’Reilly. À mon avis (mais pas seulement le mien), tout développeur Spark sérieux devrait le lire. Acheter un exemplaire pour chaque développeur de l’équipe sera un investissement très rentable.
Encouragez les développeurs à passer une certification Spark
Comment objectiver le niveau acquis par les développeurs de votre équipe suite à une formation (ou leur autoformation) ? Une des solutions peut être de les encourager (financièrement bien évidemment) à passer une certification Spark.
Au delà du niveau de maîtrise acquis, la volonté de passer une certification prouvera leur motivation et l’intérêt qu’ils portent pour cette technologie.
Les certifications proposées par Databricks semblent être les mieux réputées.
Assurez-vous que l’équipe développe avec des tests automatisés
Il m’est arrivé d’observer plusieurs fois des développeurs qui testent leurs applications sur le cluster de production tout au long de la phase de développement. Ils buildent et soumettent leurs applications au cluster de production à chaque modification du code.
Une itération dure donc au minimum plusieurs minutes comprenant :
le temps de build,
le temps d’attente sur un cluster on-premise ou le temps de démarrage d’un cluster éphémère sur le Cloud,
le temps d’exécution avec les données de production (donc très volumineuses),
le temps d'accéder aux données en sortie ou à des logs d’erreur.
Dans le pire des cas, ils font tourner le cluster de production pendant plusieurs dizaines de minutes pour se rendre compte d’une faute de frappe dans le nom d’une colonne d’un DataFrame. Je vous laisse prendre la calculatrice et estimer combien cela vous coûte, sachant qu’avec les tests unitaires, détecter une telle erreur ne prend que quelques secondes et ne consomme que les ressources du poste de développement.
Tester le code Spark directement sur les données et le cluster de production n’est acceptable que dans les cas suivants :
Lorsqu’on est dans la phase d'exploration et de recherche (souvent faite par les Data Scientists en utilisant des Notebooks ou les outils en ligne de commande : spark-shell, spark-sql, pyspark ou sparkR),
Afin de valider une application déjà testée fonctionnellement et procéder au fine tuning des performances.
Lorsque l’on passe à la phase d’industrialisation, il est nécessaire de :
développer avec des tests automatisés (ou encore mieux en TDD),
exécuter le code Spark en local avec un échantillon de données représentatif (c’est là où ça coince souvent),
tuner (si possible) les performances de l’application sur un petit cluster et un sous-ensemble de données proportionnel à la taille du cluster,
valider les performances de l'application sur le cluster de production (ou un cluster de staging) et les données de production.
De plus, les tests automatisés rendront le code plus facilement maintenable grâce à une meilleure séparation des responsabilités et réduiront le risque de régression.
J’ai une profonde conviction que rien ne documente mieux le code que les tests automatisés.
N’ayez pas peur de Scala
J’ai déjà entendu à plusieurs reprises la phrase suivante :
“Nous n’avons pas retenu Scala parce que nous n’avons pas de compétences en interne, les compétences sont plus rares sur le marché et par conséquent plus chères.”
Fausse croyance ! Ce n’est pas de compétences en Scala dont vous avez besoin mais de compétences en Spark. Pour qu’un projet Spark réussisse, il est surtout important que les développeurs aient une bonne compréhension du fonctionnement de Spark et des enjeux d’industrialisation.
Pour faire du Spark, il suffit d’avoir des connaissances rudimentaires en Scala. Il arrive même qu’un expert Scala ne veuille pas faire du Spark parce qu’il s’ennuie.
Un développeur Java suffisamment curieux et ouvert d’esprit tombera amoureux de Scala et du paradigme de la programmation fonctionnelle.
Je suis même convaincu qu’en termes de recrutement, vous allez plus facilement attirer des bons développeurs Java en leur promettant de pouvoir monter en compétence sur Scala.
Les bénéfices de Scala sont évidents :
Les nouvelles features sont en priorité ajoutées à l’API Scala car Spark est écrit en ce langage,
Scala est moins verbeux que Java de manière générale, en plus le DSL de Spark en Scala est plus élégant, par conséquent le code est plus facile à écrire et à maintenir,
Dans certains cas, Spark Scala est plus performant que PySpark,
L’API Scala est une des plus utilisées (dépassée par PySpark depuis quelque temps), par conséquent elle bénéficie du meilleur support de la communauté que les APIs Java et R,
Tous les livres sur Spark donnent des exemples de code en Scala,
La librairie de tests unitaires ScalaTest est un bijou !
Pensez à la CI/CD
Pour la petite anecdote, voici ce que j’ai entendu dire par un décideur lorsque j’intervenais sur un projet Spark dans une grosse structure, je cite :
“Nous n’avons pas besoin de l'intégration continue parce que notre priorité c’est la qualité. S’il faut passer deux semaines pour mettre en production, on passera deux semaines, mais on le fera bien.”
Combien d’incohérences voyez-vous dans cette citation ?
Pensez à mettre en place les pipelines CI/CD dès le début du projet. Cela augmentera la productivité de l’équipe en automatisant les tâches répétitives et réduira le risque de régression du service en production. On ne peut pas parler de l’industrialisation sans évoquer la CI/CD.
Pour optimiser les coûts, pensez aux clusters éphémères
L’utilisation de “clusters éphémères” (également appelés “clusters transients”) permet de tirer pleinement bénéfice du Cloud public par rapport au on-premise. Il s’agit d’un paradigme qui consiste à créer un cluster dédié à un traitement et à le détruire à la fin de ce traitement. L’article de Lucien FREGOSI vous expliquera en détail ce nouveau paradigme et vous donnera un exemple de configuration sur AWS.
La mise en place de ce mécanisme s’inscrit dans le cadre de l’industrialisation de votre projet, car il nécessite l’automatisation de la création de clusters en mode infra-as-code. Il n’est plus possible de lancer un job Spark à la main, ni de développer directement sur le cluster.
Faites accompagner votre équipe par des experts
En faisant intervenir des experts dès le début du projet, vous pouvez réaliser plusieurs recommandations de cet article à la fois :
Former l’équipe à Spark et aux bonnes pratiques de développement,
Mettre en place l’outillage DevOps (CI/CD, Supervision, Clusters éphémères, etc.),
Valider les choix d’architecture et le workflow de traitement,
Tuner les performances (format de données + code + configuration du cluster).
Le ROI positif de cet investissement est indéniable.
Qui a dit “RDD” ?
Si un jour (même après avoir suivi les recommandations de cet article), vous entendez parler de “RDD” dans votre open space, arrêtez tout et faites une réunion d’urgence !
Sans rentrer dans les détails, il s’agit d’une API bas niveau qui était la seule disponible dans les premières versions de Spark. Ensuite, de nouvelles APIs haut niveau ont été construites au-dessus des RDD en apportant de très nombreuses optimisations et de nouvelles fonctionnalités. Les différences en termes de performance (et donc d’efficience) sont très conséquentes.
Utiliser l’API RDD aujourd’hui, c’est comme coder en Assembleur à la place de C++. Il est possible de faire du code performant, mais il faut avoir un sacré niveau. Descendre au niveau de RDD ne peut être justifié que dans certains cas très particuliers.
Certains projets legacy, développés en RDD sur les premières versions de Spark, ont été migrés vers les nouvelles versions sans réécriture du code. Ils n’ont donc tiré quasiment aucun bénéfice de cette montée de version.
Certains développeurs peu curieux se mettent à utiliser les RDD sans se poser de questions après être tombés sur un exemple de code sur Internet.
Compte tenu de tout cela, si votre équipe parle de RDD, elle vous doit à minima des explications.
Conclusion
Malgré le progrès des outils, le calcul distribué reste une problématique complexe. Le nombre de projets Spark en détresse en témoigne parfaitement.
L’industrialisation est cruciale pour la réussite d’un projet informatique. Les projets Spark n’échappent pas à la règle.
Spark est un bel outil dont je suis fan. Avec cet article, j'espère avoir contribué à ce qu’il soit apprécié à sa juste valeur grâce à l’accroissement du nombre de projets réussis.
Le Scrum Master est un facilitateur. Ce n’est pas le point central de l’équipe, le hub, le chef, le dictateur éclairé, le Dieu. Il aide son équipe dans l'objectif de délivrer de la valeur dans les meilleures conditions.
La question ici n'est pas de savoir si le SM peut cumuler les casquettes de développeur et Scrum Master. Sujet qui mérite son propre billet.
Non, non. Je vais essayer de rester S.O.L.I.D. dans la recherche d'une réponse qui obviously, n'est pas 42. Je vais tenter de partager mon point de vue. Mais avant de donner mes pistes de solution, observons cet étrange personnage.
Disons-le franchement, peut-on être Scrum Master et être dépassé par la technique?
Voire ne pas être technique du tout...
"Ohh ! Don't Boo your chieftain !!!!...."
Scrum Master, un "manager" nouvelle génération ?
Si le Scrum Master est un manager, il se doit d’appliquer une des valeurs maîtresses d'un bon manager 3.0 : Trust. Sans confiance, il est inévitable de retomber dans le besoin de Command & Control aka "Je dis, vous faites".
Pire encore : "Faites ce que je dis et pas ce que je fais", situation classique qui décrédibilise rapidement et totalement le-dit manager.
Il faut avoir cette conviction d'accompagnateur de l'équipe pour obtenir l'alignement et l'autonomie suffisante pour ne pas sombrer dans le chaos.
Une confiance réciproque qui inspire l'équipe.
"The best way to find out if you can trust somebody is to trust them" — E. Hemingway
J'ai également la conviction que pour tenir le rôle d’un bon Scrum Master, cette personne ne doit pas coder sur le produit. Dans le simple respect d'une des valeurs de Scrum : FOCUS (concentrer).
Il y a aujourd’hui pléthore de raisons de se distraire (mail, téléphone, Slack, réunions, machine à café, Nerf, babyfoot, feuille de temps, LinkedIn, Facebook interne, etc…). Un >= peut rapidement devenir un simple > et c’est le bug en prod. Le Scrum Master doit favoriser la concentration de l’équipe.
Imaginez-moi, Scrum Master qui :
Encourage
Aide à rester focus sur la tâche que l’équipe s’est engagée à réaliser lors du Daily Meeting ou Sprint Planning
À l’affût du moindre obstacle pour le faire disparaître,
À observer et protéger d’éventuels risques internes ou externes,
À rechercher LA nouvelle activité à la mode pour dynamiser le groupe,
À améliorer le Visual Management,
À accompagner l’Architecte à formuler un mail un peu trop chargé en vitriol
Etc, etc....
Tout ça pour dire que je risque de passer du coq à l'âne pour le bien de l’équipe...
HEY MINUTE PAPILLON !! … mais je suis en plein dans le "Faites ce que je dis pas ce que je fais !" ...
Le Scrum Master est déjà suffisamment schizophrène, il est préférable pour le produit et l'équipe de ne pas pousser le bouchon.
Mais c’est un mal pour un bien. Un sacrifice nécessaire pour que la prise de recul soit efficace et apporte les meilleurs clés pour dé-cadenasser les ralentisseurs de livraison de valeur.
En tant que Scrum Master, je ne suis plus le manager qui donne des ordres ni celui qui dit quoi faire en répartissant le travail entre les membres de l’équipe.
Je dois être ce Manager 3.0 qui accompagne les gens pour les faire grandir, qui recherche la moindre chose à améliorer, qui rend son équipe la plus autonome pour prendre les bonnes décisions et accompagne au changement le reste des acteurs du projet en faisant attention à ne surtout pas faire de micro-management.
Mais ça ne va pas se coder tout seul ...
OK admettons ce que je viens de dire, le Scrum Master ne code pas...
En tout cas, pas pour le produit.
C’est donc l’équipe de développement qui est en charge de le faire.
Mais qui peut mettre en question la qualité du travail fait ? Qui fait des remarques sur l’implémentation ? Qui pousse l’utilisation d’une technologie ?
Que fais-tu de l'honorable Chef de Projet technique ??
Il faut rendre à César ce qui appartient à César, le code c'est l’équipe de développement. Cette équipe étant multidisciplinaire et d’expérience hétérogène suffisante pour le développement du produit, elle fera les choix techniques.
Bon! On dit code, mais un produit ne se résume pas qu’au code.
Il est souvent fait le raccourcis qu’avec l’Agilité c’est moins de documentation. Trois idées sur un post-it et hop! on livre.
La communication est prépondérante certes, mais la documentation reste à faire à bon escient.
organizations which design systems ... are constrained to produce designs which are copies of the communication structures of these organizations.— M. Conway
Alors, pour revenir à notre Scrum Master, la situation est que s’il est certain de ses compétences techniques ET qu’il participe activement à l'évolution du produit, alors qu’il partage son savoir et point de vue sur le sujet.
Sinon pour ne pas citer Big Lebowski :
"Shut the fuck up Donny you're out of your element !"
J'aime plus le voir comme le réflecteur du code du développeur et par bienveillance l'interroger sur l'intention de son code. En principe, le simple fait de faire le canard en plastique à côté de quelqu'un et de lui demander : "Pourquoi tu fais ça ?" permet de le faire s’interroger à haute voix et prendre conscience d'une éventuelle anomalie.
Saturnin et les développeurs
Néanmoins avant de diverger plus, ... verger plus... l'objectif ici c'est de répondre aux Scrum Master les moins (ou pas) techniques.
Pour être en mesure de challenger l’équipe à être de bons artisans du code, voici plusieurs pistes que j'utilise pour continuer à garder cette confiance de la team et le focus sur mes activités.
DOD (aka Definition Of Done)
Souvent un artefact vite oublié ou en tout cas le moins respecté dans des équipes juniors (ou pas). Le DOD. La Definition Of Done. Cette check-list que la team a construite au fil du temps pour s'assurer qu'un récit est Done à 100% et pas le :
- "J'ai terminé à 90%" .....
- "Hein ?? Mais c'est terminé ou pas ???? Tu veux un 'Ko Soto Gari' sur la moquette de l'open space ?"
Oui le DOD est un bon moyen de suivre la qualité technique. En quelques règles, il est facile de constater les bonnes normes de développement que l’équipe auto-organisée s’est imposée.
Par exemple, on peut retrouver dans la checklist des choses comme :
Build CI/CD vert
Mis à jour du board (Kanban, JIRA, GitLab, Obeya, Redmine, etc.)
Indicateurs SonarQube constant ou en progression (Couverture des Tests Unitaires, Bugs, Code Smell, etc.)
Automate de test : OK
Revue de code par un sénior ou Pair-programming
Mutation testing
Documentation Technique, Wiki, Dossier d'Architecture Technique : OK
etc, etc...
Du Done c’est TTC. Toute taxe comprise. Un récit Done, c’est le dev, les TU, la doc, les tests, l’installation, etc.
Mais en général les membres d'une équipe savent très vite rappeler un mouton qui se soustrait de la bergerie pour ne pas faire ses TUs.
… mouai, Back to reality, à croire que la faute est exclusivement celle des développeurs.
Le non-respect du DOD peut aussi être dû à la pression des stakeholders ou du PO qui ne comprennent pas toujours l’ensemble des éléments du DOD.
Éduquer ces personnes est du rôle du Scrum Master via des Serious Games, vie ma vie de développeur, visite régulière des locaux et de l'open space, venir aux review, etc.
SonarQube
SonarQube est un bon moyen de challenger l'équipe sans être trop technique.
Le plus fun dans l'histoire c'est que même si pour vous "Public methods should throw at most one checked exception" c'est du Mandarin, il suffit de cliquer sur le détail. SonarQube vous donne une courte explication ainsi qu'un exemple de code non-compliant et une solution de code compliant.
Si vraiment ça ne vous parle pas, reste à vous ensuite de demander “Est-ce vraiment critique pour le produit ?” à Google, StackOverflow ou un architecte hagard qui ne sais plus s’il est dans la team ou pas.
SonarQube est plein de bons indicateurs pour vous aider à communiquer et challenger votre équipe. Une fois que vous aurez trouvé les KPIs pertinents, libre à vous de crâner à la machine à café avec un tech lead.
Le SM doit être vigilant et rappeler l’importance de ces KPIs à la Dev même s'ils font peur ou mal. Team et PO doivent surveiller et réduire leur dette avec SonarQube.
Si personne ne le fait, vous devriez montrer à la team qu'elle court un risque si elle ne la prend pas en considération en écrivant du meilleur code ou en payant un peu la dette chaque itération sous peine un jour ... BIMMM c’est la crise des Subprimes !
Le PO doit comprendre qu’il doit octroyer du temps aux Dév. pour que son produit ne soit pas une bombe à retardement.
Dans ce monde rien n'est certain, à part la mort et les dettes...
Dans le cas contraire, si la dette n’est pas prise au sérieux les conséquences peuvent être fâcheuses :
L'estimation des Stories va vite grimper pour prendre en compte cette dette,
Votre burnup ou burndown va commencer à faire le yoyo ou l'encéphalogramme plat,
Pareil pour la vélocité de la team. C'est aussi pourquoi ON NE PILOTE PAS UN PRODUIT AVEC LA VÉLOCITÉ MAIS AVEC DE LA VALEUR MÉTIER pu§@$µ*#§!!!!!!! .... pardon
Vous portez le bouclier de l'équipe. Si la team exprime en rétrospective qu'elle peine à prendre de nouvelles histoires sur tel sujet car une classe controller est un “Cauchemar en Openspace”, vous devez le faire entendre au PO.
Sensibilisez-le s'il n'a pas compris. Il doit optimiser son attendu pour le prochain sprint pour que l'équipe éponge un peu la dette en s'attaquant au refacto de la classe.
Attention néanmoins à l’infobésité. Sonar est riche, mais n’explique pas tout. Surtout si l’information est prise de manière statique. Le bon sens et l'expérience de l'équipe doivent prévaloir sur les metrics rapportées.
Mutation Testing
Le DOD peut exiger un seuil minimal de couverture de test (Quality Gate dans Sonar).
Enough is not good Enough.
L’effet pervers dans ce cas est qu’une méthode peut être soumise à un test, mais y a-t-il vraiment une assertion ? Couvre-t-il tous les cas de figure ? Doit-il couvrir tous les cas de figure ? Ce test n’est-il pas un test d’intégration ?
Il y a un truc magique pour ça ! Le Mutation Testing.
Pour faire simple, le Mutation Testing est une opération qui va modifier des choses dans le code (opérateurs, suppression de blocs, etc.), afin de vérifier que les tests associés ne passent plus. En faisant cela, vous vous assurez que le code est bien testé, pertinent, et non simplement couvert. (Cf. annexe pour plus de détails)
Comme le jeu c'est l'apprentissage, en voilà un très drôle à manier avec bienveillance : demander à l'équipe si elle est 100% confiante dans ses Tests Unitaires. (Et qu’elle n’est pas au fait du Mutation Testing évidemment 😆).
Etape 1 Prendre une équipe (qui fait des Tests Unitaires) et poser la question
En principe, il va être tellement simple répondre au SM (surtout s'il n'est pas trop technique) :
" - Dude! On est la dream team, des Hot Shots !! Nos TU c'est ceinture et bretelles ! En plus on fait du TDD"
Traduction : "On est des experts, tu nous fais pas confiance ? Tiens en plus cadeau, je te balance un mot dans ton jargon du parfait Dev Agile, ça va passer crème :)"
Etape 2 Prendre le code en local et mettre en place le Mutation Testing
Regarder le rapport et vraisemblablement... vous aurez de quoi rigoler lorsque vous reposerez la question candidement le lendemain.
Une fois l'expérience faite, il est évident qu'il faut le prendre avec humour. Tu me troll, je te troll. Reste maintenant à comprendre la raison du manque de qualité du TU. (Temps, expérience, formation, périmètre, outillage, etc.)
Le mutation testing va rapidement pouvoir aider l’équipe à se challenger sur la couverture de test, mais surtout savoir si elle est efficace. #Sérénité
À ajouter d’urgence dans votre boite à outil ou à votre DOD si ce n'est pas encore le cas !
Acceptance Test
Après tout, une des valeurs de l'agilité c'est bien "Working Software over comprehensive documentation".
Tester c'est douter. Dans le doute, reboot. Tester c'est rebooter ?
Une story devrait être autant que possible I.N.V.E.S.T. et répondre à la convention 3C (Card, Conversation, Confirmation). Confirmation pour dire qu'il doit y avoir un minimum d'information pour valider que l'objectif est bien atteint.
Cette confirmation dans une story peut prendre diverses formes. Un scénario de test fonctionnel dans HPALM ou Xray ou même Excel. Pour les plus adeptes de pratiques Agiles, il y a le Behaviour-Driven-Development.
Le BDD propose de mieux conduire le développement sur la base de la conversation et des exemples concrets. Une autre forme plus stricte comme l'ATDD propose une surcouche à la pratique TDD – pratique hautement reconnue pour assurer une bonne qualité de code.
En enseignant et challengeant l'équipe sur des pratiques BDD ou l'ATDD, vous ajouterez une couche supplémentaire vers l'excellence technique en couvrant des aspects aussi bien fonctionnels que techniques. Et en bonus de la non-regression.
C’est ceinture, bretelle et parachute !
Tester, présenter, vulgariser l’utilisation de ces pratiques dans sa team est aussi dans la mission du Scrum Master. Faire adopter ces techniques, c’est aussi challenger l'équipe sur le chemin de la production à haute valeur ajoutée.
Visual Management
Suivre le kanban, le burnup ou burndown est un bon moyen également de humer les odeurs du code.
En effet, si ce n'est qu'au dernier moment, en fin de sprint que la courbe du Done rencontre enfin l'objectif alors que tout le long du sprint l'encéphalogramme était plat.
Alerte Capitaine !
Il est facile d'imaginer comment les stories ont été bouclées. Si en plus l'équipe ne cache pas sous le tapis quelques TU au passage.
Savoir interpréter les courbes c'est important. Mais ça reste de l'interprétation.
La lecture de vulgarisation
Des livres comme "Clean Code", "The Software Craftman" ou “The Clean Coder” sont de bonnes référence pour s'initier aux bonnes pratiques de développement. Faut dire qu’un des auteurs n’est autre que “l'oncle” Bob C. Martin, l'un des signataires de l'Agile Manifesto.
Des acronymes comme KISS, YAGNI, DRY, test FIRST doivent être dans votre vocabulaire.
J'ai eu la chance d’avoir une présentation sur la solution de Promyze qui se plug sur le Sonar et apporte une dose supplémentaire d’analyse du code statique, des objectifs de groupe et de la gamification.
De quoi ajouter du fun à la correction de violations Sonar.
Attention néanmoins à ne pas en faire un outil de flicage de la team. C'est un outil pourla team et rien d'autre.
La puissance du groupe
Honte à toi si tu donnes des objectifs pour l'évaluation de fin d'année !
Utiliser la force du groupe lors de MOB programming (Séance coding de groupe) ou de randori coding dojo. En facilitant, la session et en déléguant.
La bonne vieille rétrospective
Enfin en tendant l'oreille plus souvent dans le l'open space, vous pourrez capter le son caverneux d'un développeur hurlant dans sa barbe après le commit de 600 lignes de code sans commentaire et indentation.
Challenger le à challenger son collègue sinon pourquoi ne pas concocter un retrospective qui va faire jaillir
Passe ça au PO...
Pas d’US, pas de code. Pas de code, pas de produit. Pas de produit, ... pas de produit.
Et du coup, qui se charge de faire des US ? … Et bien notre bon PO.
Ou, Y a-t-il un PO dans l'avion ?
Écrire du Français, ce n’est pas technique. Ah bon ? Si le développeur reçoit une documentation torchon, malgré tout l’effort et la bonne volonté, inévitablement, il va coder un torchon.
Une technique (du grec τέχνη ou technè) est une méthode ou un ensemble de méthodes, notamment dans les métiers manuels (menuiserie, art de la forge, etc.), où elle est souvent associée à un savoir-faire professionnel. —Wikipedia
Si votre PO écrit des stories en utilisant des méthodes comme :
Lorsque votre PO n’est pas issu du monde de l’informatique et qu’il est du métier, détaché dans le département informatique, vous, Scrum Master, vous devez l’aider à survivre dans la jungle des développeurs.
Le PO est dans la team. Il n’y a pas que la Dev Team dans un projet. Connaître ou même maîtriser les techniques de rédaction de Stories est nécessaire pour un bon Scrum Master.
Dans le cadre de certains projets, il peut être nécessaire d’avoir un Business Analyst (un fonctionnel) pour aider le travail de raffinage. Il faudra lui aussi l’accompagner.
C’est encore plus vrai lors d’un passage à l'échelle. Votre PO ne sera plus en mesure d’assumer seul le travail de rédaction des histoires. Le SM aura pour mission d’assurer l'alignement de tout ce beau monde.
Un Scrum Master devrait donc connaître les techniques du PO. Idem pour l’UX/UI, Architecte, Ops, team support, etc...
J'l'avais dit ... schizophrène.
Pour conclure
Il existe encore bien d'autres moyens pour pallier la non-expertise technique. Mais il ne faut pas oublier de faire confiance à l'équipe.
Vous êtes Scrum Master et vous n'arrivez pas à challenger la technique, n'essayez pas !
Sauf si vous prenez part au développement.
Demandez de l'aide à un Senior/Lead Développeur. Une équipe, surtout avec de jeunes pioupiou, doit être accompagnée d'un senior.
Surtout n'oublions pas que le Manifest Agile a été rédigé par des développeurs :)
Les 12 principes s'appliquent si déjà on écrit et run correctement un print("Hello world").
The experience of pain or loss can be a formidably motivating force. — John C. Maxwell
Comprendre le quotidien et les problématiques d’une Team sera un avantage considérable pour anticiper les points de blocage.
Mon avis pour passer d'un bon Scrum Master à un très bon Scrum Master est de manier un minimum la langue de la team : la technique.
Ou comment un simple stage se transforme en une véritable mission de mentoring !
Les débuts en tant que stagiaire
Jour 1:
Ce n’est pas un matin comme les autres, on quitte enfin notre statut d’étudiant pour entrer en entreprise en tant que stagiaire mais tout de même c’est un grand jour, premier jour de notre entrée dans la vie active ! Nous sommes accueillis par un petit déjeuner puis par une présentation globale de l’entreprise et son système de fonctionnement.
Semaine 1 & 2 :
Nous nous sommes mis rapidement dans le bain et nous sommes montés en compétences sur les frameworks Angular et Spring durant les deux premières semaines. Nous avons même eu l’opportunité de pouvoir suivre une formation avancée de Spring.
Semaine 3 :
Le fameux sujet de stage tant attendu !
Projet :
Une refonte totale d’une application de gestion de sites de traitement de déchets développée il y a plus de dix ans. Ippon nous a fait confiance en nous intégrant dans une équipe Ippon sur un projet client CAC 40.
Objectifs:
Développer des fonctionnalités
Corriger les anomalies
Proposer des améliorations
Ce projet a été développé avec l’outil JHipster (un générateur d'application libre et open source utilisé pour développer rapidement des applications Web modernes en utilisant Angular et le framework Spring ).
Cela nous a donc permis de pérenniser nos nouvelles connaissances d’Angular et de Spring. Le fait d’avoir été dans une équipe IPPON plus expérimentée nous a offert un environnement rassurant.
Ingénieur d’études chez Ippon, une finalité mais surtout le pacte de la confiance
Trois mois ont passé et Ippon nous a fait des propositions d’embauche à des postes d’ingénieur d’études en CDI alors même que nos diplômes n’étaient pas encore validés et qu’il nous restait trois mois de stage. Inutile de vous dire que c’était très encourageant et que cela nous a permis de penser que le mémoire et la soutenance de stage ne seraient plus qu’une formalité.
En tant que nouveaux IPPON, nous avons participé au on-boarding de trois jours qu’Ippon organise pour les nouveaux arrivants. Il est composé de:
Présentation des différents métiers, organisation, programme de formation, chez Ippon
Ateliers: initiation JHipster, initiation Agilité, développement personnel avec
Une soirée avec une Murder Party au RoofTop
C’est parti ! Une mission intéressante pour un acteur bancaire
Suite au projet Suez, Nicolas, commercial dans le vertical bancaire, nous a proposé une mission chez “NEW Bank” en tant que développeur Back-end que nous avons accepté. Il nous a aidé à préparer l’entretien que nous avons passé avec brio.
“NEW Bank” est une néo-banque mobile, son objectif est de faciliter les démarches bancaires de l’utilisateur en les "digitalisant" sur support mobile. La partie back-end est développée avec le framework Spring.
Nous avons intégré la nouvelle équipe Paiement composée de 8 développeurs et d’un Scrum Master. Notre mission consiste à développer des fonctionnalités autour de l’univers paiement comme l’envoi et la demande d’argent par SMS, ainsi que de corriger les anomalies. Être en mission chez “NEW Bank”, nous permet aujourd’hui de participer à un projet de grande envergure avec de nombreuses entités (Core Banking, Partenaires Extérieurs, Marketing, Coach Agile …), avec des processus industriels, dans un environnement agile. Nous avons la chance d’être entouré dans l’équipe d’autres développeurs Ippon ayant de l’expérience ce qui nous permet de nous améliorer et d’apprendre au quotidien.
J’espère que nous vous avons donné envie, voici quelques TIPS sur le process de recrutement
Le processus de recrutement
Notre recrutement s’est effectué en 3 étapes : le coding challenge, l’entretien avec la Talent Acquisition Specialist et l’entretien technique avec un leader technique.
Lecodingchallenge Le coding challenge se fait chez soi. Il est composé de 3 exercices qui ont différents niveaux de difficultés qu’il faut résoudre dans un temps imparti. Ne stresse pas! Ce coding challenge n’est pas insurmontable et avec de la préparation les deux premiers exercices sont réalisables sans être un développeur fou. De plus, le résultat de celui-ci n’est pas un facteur majeur pour le recrutement mais ce sont les deux points suivants qui le sont.
L’entretien avec la Talent Acquisition Specialist On passe du temps avec un recruteur et on échange sur notre parcours, sur nos envies et aussi sur IPPON. Sois toi même, exprime tes envies, raconte ta vie ! Les recruteurs veulent plus en savoir sur toi et pas uniquement sur ton parcours informatique. Raconte tes différentes expériences, tes hobbies, ce qui fait de toi la personne que tu es et tout ira bien !
L’entretien technique On échange avec un développeur Ippon Sénior qui nous donne des petits exercices techniques et nous explique les différentes technologies qu’on sera à même de rencontrer dans nos prochaines missions. Là, c’est une super occasion de prendre une petite leçon (dans le bon sens du terme)! Les Ippons sont dans le partage et savent que nous n’avons pas beaucoup d’expériences quand nous sortons de l’école, ils vont être compréhensif et vont te donner plusieurs conseils tant techniques que pour ton entrée dans le monde professionnel.
L’objectif de cet article est de proposer une solution de déploiement d’une application dans un cluster Kubernetes déployé sur AWS.
Nous allons surtout aborder l’exposition du service sur Internet (enregistrement du nom de domaine, création du certificat SSL) par configuration d’une ressource Kubernetes Ingress et expliciter sa prise en compte par des modules Kubernetes choisis.
L’application à déployer est une application Java autonome qui fournit une API REST de gestion de livres (nommée books-api).
La lecture de cet article nécessite une connaissance basique des concepts Kubernetes (Pod, Service, Deployment).
Plan
Dans la section Déploiement Initial, nous commençons par réaliser un premier déploiement de l’application ; l’application est accessible à l’intérieur du cluster.
Dans la section Exposition du Service, nous exposons le service sur Internet ; le service est accessible mais pas via le bon nom de domaine.
Dans la section Enregistrement du Nom DNS, nous créons un enregistrement DNS pour que le service soit accessible via le nom de domaine attendu.
Dans la section Création d’un certificat, nous créons un certificat SSL pour exposer l’application en HTTPS.
Les 4 sections Déploiement Initial → Création d’un certificat sont structurées de manière uniforme : Choix d’un module Kubernetes qui répond à la problématique, Configuration Ingress et Validation de la solution.
Dans la section Schéma d’architecture, nous donnons une vue globale de l’architecture déployée en termes de briques techniques AWS et composants K8s.
Déploiement Initial
Pour déployer l’Application, nous avons configuré les ressources K8s suivantes :
1 Deployment qui spécifie comment déployer l’application
1 Service qui fournit un point d’accès à l’application, interne au cluster
Comme indiqué par la ligne de commande kubectl ci-dessous, le Service a une adresse IP privée au cluster (CLUSTER-IP en 10.xx.xx.xx) et ne possède pas d’adresse IP externe (EXTERNAL-IP ). Le service n’est donc pas exposé sur Internet. Le service est accessible en interne au cluster (par tous les autres services) via son nom (le cluster gère un DNS interne).
$> kubectl get service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
books-api ClusterIP 10.111.224.177 <pending> 80:31892/TCP 9s
Validation
Voici un exemple d’appel du service à partir d’un noeud du cluster
$> curl http://10.111.224.177/api/books
[{"id":1,"title":"Design Pattern","author":"Erich Gamma, John Vlissides, Ralph E.. Johnson et Richard Helm"},{"id":2,"title":"Effective Java","author":"Joshua Bloch"}]
Exposition du Service
Comme expliqué par la documentation K8s, la solution préconisée pour exposer un Service K8s en dehors du cluster, est de configurer une ressource Ingress.
Nous utilisons l’implémentation ingress-nginx basée sur NGinx.
Nous avons installé ingress-nginx en utilisant ce package helm (format de package kubernetes) trouvé sur Helm Hub (référentiel de packages Helm prêts à l’emploi).
Un package helm s’installe dans une ligne de commande (via un helm install) avec possibilité de surcharger des valeurs par défaut du package (option --set).
Pour l’installation de ce package helm, nous n’avons pas eu besoin de surcharger les valeurs par défaut du package.
Pour exposer les services du cluster (déployé dans un cloud AWS), le Service ingress-nginx :
Déploie un serveur NGinx dans le cluster
Crée un Load Balancer AWS “classic” en frontal du serveur NGinx créé.
Pour que le Service ingress-nginx gère un Load Balancer AWS, nous avons associé au profil des instances EC2 du cluster les autorisations nécessaires (lister/lire/écrire) sur les ressources elasticloadbalancing.
La ligne de commande ci-dessous affiche les informations du contrôleur ingress-nginx
Le contrôleur possède une adresse IP externe (en xx.elb.amazonaws.com).
L’adresse externe du contrôleur NGinx est l’adresse du Load Balancer AWS
$> kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
ingress-nginx-controller LoadBalancer 10.110.129.140 aab0825d933a14332bb50426fac23040-116335780.us-east-1.elb.amazonaws.com 80:31147/TCP,443:32405/TCP 2m28s
Configuration Ingress
Dans la configuration de la ressource Ingress, il faut spécifier :
Le nom de domaine de l’application (books-api.ippon.fr)
Les règles de redirection des requêtes HTTP reçues vers le Service K8s.
L’implémentation Ingress à utiliser
Voici la configuration Ingress de notre application.
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
annotations:
kubernetes.io/ingress.class: nginx (implémentation ingress-nginx)
name: books-api
spec:
rules: (règles de redirection)
- host: books-api.ippon.fr (nom de domaine de l'application)
http:
paths:
- backend:
serviceName: books-api (nom du Service)
servicePort: 80
path: /
Au déploiement de l’Ingress, la configuration du serveur NGinx est modifiée pour intégrer les règles de redirection HTTP. Ainsi, toutes les requêtes envoyées au host books-api.ippon.fr sont envoyées au Service books-api
Validation
Voici deux appels du service exposé envoyés au Load Balancer en passant ou pas le nom de domaine de l’application.
Le premier appel est KO car il ne respecte pas les règles de routage de l’Ingress (requête non envoyée au Host books-api.ippon.fr)
Le second est OK car le Host est passé via un header HTTP
# appel du service exposé via le Load Balancer (Routage KO)
$> curl https://aab0825d933a14332bb50426fac23040-116335780.us-east-1.elb.amazonaws.com/api/books
default backend - 404
# appel du service avec le nom de domaine passé en Header (Routage OK)
$> curl -k -H "Host: books-api.ippon.fr" https://aab0825d933a14332bb50426fac23040-116335780.us-east-1.elb.amazonaws.com/api/books
[{"id":1,"title":"Design Pattern","author":"Erich Gamma, John Vlissides, Ralph E.. Johnson et Richard Helm"},{"id":2,"title":"Effective Java","author":"Joshua Bloch"}]
Enregistrement du Nom DNS
Faute de pouvoir configurer le nom de domaine du Load Balancer créé par ingress-nginx, nous avons créé un enregistrement DNS qui associe le nom de domaine de notre application (i.e. books-api.ippon.fr) au nom de domaine du Load Balancer (du contrôleur ingress-nginx créé à l’étape précédente).
Le module external-dns permet justement de créer ces enregistrements dans une zone hébergée Route 53 (DNS Amazon).
Nous avons installé external-dns en utilisant ce package helm en spécifiant le fournisseur DNS (aws), le type de zone hébergée (public) et l’id de la zone hébergée ({{hosted_zone}}).
La mise en place d’external-dns ne nécessite pas de changer la ressource Ingress.
Au déploiement de l’Ingress, le contrôleur external-dns crée deux enregistrements DNS (dans la zone hébergée indiquée)
Un enregistrement ALIAS vers l’adresse externe de l’Ingress
Un enregistrement TXT qui spécifie l’origine de l’enregistrement (le nom de l’Ingress)
Pour que le Service external-dns soit capable de gérer un Load Balancer AWS, nous avons associé au profil des instances EC2 du cluster les autorisations nécessaires sur les ressources route53 . Cette information se trouve dans la documentation officielle.
Validation
Voici un exemple d’appel du service exposé en utilisant le nom de domaine :
L’option “-k” est nécessaire car nous n’avons pas encore créé le certificat SSL
# appel du service exposé avec le nom de domaine (Routage OK)
$> curl -k https://books-api.ippon.fr/api/books
[{"id":1,"title":"Design Pattern","author":"Erich Gamma, John Vlissides, Ralph E.. Johnson et Richard Helm"},{"id":2,"title":"Effective Java","author":"Joshua Bloch"}]
Création du Certificat
Dans cette section, nous allons créer le certificat via le module cert-manager. Nous avons installé cert-manager en utilisant ce package helm (sans surcharge de paramètres du package helm).
Nous configurons cert-manager de manière à ce qu’il crée les certificats via l’autorité de certification Let’s Encrypt.
Let’s Encrypt implémente le protocole ACME HTTP qui permet à un client de demander la création d’un certificat pour un nom de domaine. Le client doit prouver (via un challenge) qu’il est propriétaire du nom de domaine. Il existe différents challenges (HTTP-01, DNS-01, …) qui ont des contraintes différentes.
Dans notre cas, nous avons choisi d’utiliser le challenge DNS-01. Dans ce challenge, le client crée un enregistrement TXT de nom _acme-challenge.<YOUR_DOMAIN> valorisé avec un token fourni par Let’s Encrypt.
Pour que cert-manager puisse demander la création de certificats, il faut configurer un Issuer (ou un ClusterIssuer).
Issuer : Autorité de Certification (i.e. Let’s Encrypt).
ClusterIssuer : Autorité de Certification visible au niveau du cluster (et pas seulement dans un namespace)
apiVersion: certmanager.k8s.io/v1alpha1
kind: ClusterIssuer
metadata:
name: letsencrypt-issuer
spec:
acme:
# The ACME server URL
server: https://acme-v02.api.letsencrypt.org/directory
# Email address used for ACME registration
email: melkouhen@ippon.fr
# Name of a secret used to store the ACME account private key
privateKeySecretRef:
name: letsencrypt-issuer
# Enable the DNS-01 challenge provider
dns01:
providers:
- name: dns
route53:
region: us-east-1
Configuration Ingress
Pour générer le certificat, il faut d’abord créer une ressource Certificate.
Le Certificate représente une demande de création du certificat (envoyé à l’Issuer). Si les challenges passent, cette demande se conclue par la création d’un certificat stocké dans un secret kubernetes (books-api-cert).
Route 53 gère les enregistrements DNS de l’application (dans une zone hébergée)
ELB redirige les requêtes HTTP issues d’Internet vers le cluster K8s
K8s est le cluster où est déployé l’application
Conclusion
Dans cet article, nous avons déployé une application dans un cluster Kubernetes. L’application est accessible en HTTPS sur un nom de domaine spécifique.
Kubernetes est extensible ! L’exposition de services est réalisée par trois contrôleurs (ingress-nginx, external-dns, cert-manager) qui se basent sur un même objet Ingress. Le contrôleur cert-manager étend le système en définissant de nouveaux types de ressources nécessaires à la gestion de certificats.
Kubernetes s’intègre au cloud ! Le déploiement se base sur l’utilisation de services Cloud publics (DNS Route 53, Autorité de Certification Let’s Encrypt).
La construction d'un Data Warehouse est assez similaire au développement d'une application comprenant une BDD relationnelle comme couche de persistance d'un point de vue projet. Vous avez autant (voire plus) de contraintes qui nécessitent une automatisation de la gestion du cycle de vie du schéma de données :
Vous avez besoin de gérer plusieurs environnements (PROD, TEST, DEV, etc.) afin de pouvoir développer de nouvelles features sans risquer de mettre en péril le service et les valider fonctionnellement avant de déployer en production.
Vous avez des pipelines d’ingestion de données (ETL/ELT) et des Dashboards (DataViz) à versionner afin de suivre l’évolution du schéma de données nécessaire pour ajouter des nouvelles features.
Vous voulez (je l'espère en tout cas) faire profiter les utilisateurs des nouvelles features le plus rapidement possible sans passer votre vie à les mettre en production.
Vous avez donc tout intérêt à mettre en place les pipelines CI/CD dès le début de projet, et je vais vous montrer comment le faire facilement et rapidement pour Snowflake.
Le présent article est un retour d'expérience d’un projet récemment réalisé par Ippon dont la partie CI/CD était sous ma responsabilité. L’article n'a pas pour prétention d'être exhaustif ou de détenir la vérité absolue. Néanmoins, il vous donnera un bon point de départ pour vous lancer dans la construction de Data Warehouse avec Snowflake en mode DevOps.
Pourquoi Sqitch ?
Comme beaucoup de mes collègues je suis familier avec l’outil bien connu Liquibase (il fait partie de la stack JHipster), je voulais donc tout naturellement l’utiliser pour Snowflake. Le problème est que Liquibase ne supporte pas Snowflake nativement. Il existe une extension tierce, mais le projet ne semble pas être très actif. Le dernier commit date d’il y a plus de deux ans. Pour cette raison, je ne l'ai pas retenu.
Suite à mes recherches sur le forum de Snowflake, je suis tombé sur des retours positifs à propos de Sqitch, un outil similaire à Liquibase. Je l’ai installé (avec quelques douleurs quand même) et testé avec Snowflake, tout fonctionnait comme prévu. De plus, ce projet fournit le Dockerfile permettant d’utiliser Sqitch via un container Docker, ce qui m’a permis de gagner du temps lors de la mise en place des pipelines CI/CD sur Gitlab.
L’installation de Sqitch en local et son utilisation sortent du périmètre de cet article. Je vous laisse lire le manuel de Sqitch pour Snowflake. Cette présentation vous aidera à comprendre ses concepts rapidement.
Quels objets confier à Sqitch ?
Dès le début du projet, vous avez un choix à faire : décider quels types d’objet Snowflake vous allez gérer via Sqitch. Ce choix impacte la réalisation de vos scripts de migration et le workflow de la CI.
La hiérarchie des objets de Snowflake :
On distingue deux approches différentes :
Automatiser uniquement la gestion du cycle de vie des objets appartenant à une Database (Schemas, Tables, Views, etc.).
Gérer également les objets globaux.
La première approche a le mérite d’être simple. Pour détruire l’ensemble des objets créés par la CI, il suffit de supprimer la base de données. Il n’y a pas besoin de générer dynamiquement les noms des objets globaux en fonction de l'environnement.
L'inconvénient de cette approche est qu’elle ne permet pas la séparation des environnements au sein d’un même compte comme le préconise l’article d’Arnaud COL sur la gouvernance Snowflake. Vous serez obligés de créer des rôles statiques cross-environnement et de leur affecter les droits via scripts Sqitch sur les objets qu’ils créent. Gérer les droits à la main serait fastidieux, vous auriez perdu tout l’intérêt de l'automatisation.
Nous avons privilégié la deuxième approche en décidant de gérer le cycle de vie des Warehouses et des Roles par Sqitch.
Les avantages de cette approche :
Les rôles dédiés à leurs environnements permettent de restreindre les accès aux données et aux ressources de production (on peut donner à un utilisateur un rôle ayant les droits sur l'environnement de test sans lui accorder les mêmes privilèges sur l’environnement de production).
Les Warehouses dédiés à leurs environnements permettent de garantir que le service en production ne soit pas impacté par une quelconque activité sur un autre environnement. Cela permet également de suivre les coûts générés par chaque environnement.
Cette approche permet de créer des environnements identiques sur des comptes Snowflake différents et donc de les isoler totalement. Nous n’avions pas besoin d’aller jusque là dans le cadre du projet réalisé.
En revanche, cette approche impose quelques contraintes :
Elle nécessite un workflow plus complexe pour valider les scripts Sqitch par la CI. Il est facile de cloner une base de données Snowflake (zero-copy clone), mais ce n’est pas le cas pour l’ensemble de l’environnement qui intègre maintenant les Warehouses et les Roles. Vous allez voir le workflow que j’ai élaboré dans le paragraphe dédié.
Elle demande plus de rigueur lors du développement. Si vous avez mis l’environnement de DEV dans un état incohérent et que vous souhaitez repartir from scratch, vous allez devoir supprimer à la main non seulement la base mais aussi tous les Warehouses et Roles associés, ce qui vous fera perdre du temps.
Elle nécessite une technique qui permet de lier les objets globaux à un environnement dans les scripts Sqitch. Dans le paragraphe suivant, je vous donne l’astuce que nous avons utilisée.
Comment associer des objets à leurs environnements ?
Databases, Warehouses et Roles sont des objets globaux au sein d’un même compte Snowflake. Le seul moyen de les grouper par environnement est de respecter une convention de nommage. Même sans parler d’automatisation, préfixer les noms de ces objets par le nom de leur environnement constitue une bonne pratique.
La première idée qui vient à l'esprit est de passer le nom de l’environnement en paramètre de commande Sqitch :
> sqitch deploy <URI> --set env='TEST'
À l’exécution, Sqitch remplacera dans les scripts toutes les occurrences de &env par “TEST”.
L'inconvénient de cette approche est qu’il y a un risque de conflit entre ce paramètre et celui qui indique la base de données. Exemple :
De plus, la base de données à laquelle Sqitch va se connecter peut être configurée de trois façons différentes :
dans l’URI (exemple ci-dessus),
dans le fichier ~/.snowsql/config,
via la variable d'environnement SNOWSQL_DATABASE.
Pour éviter cette collision, et garantir que les requêtes s’exécutent sur la bonne base de données, il vous faudra commencer tous vos scripts par la requête :
USE DATABASE &env_DB;
ou utiliser le nom complet pour chaque objet. Exemple :
ALTER TABLE &env_DB.SALES_SCH.CUSTOMER ...;
Cela augmente considérablement le risque d’erreur. J’ai donc trouvé une autre solution qui consiste à déduire le nom de l’environnement du nom de la base de données :
SET env = split_part(current_database(), '_', 1);
On en a besoin uniquement dans les scripts qui manipulent les Warehouses et Roles. Il y a donc moins de code à écrire, moins de paramètres d'exécution, soit moins de risque d’erreur.
Que doit-on attendre de la CI/CD ?
Quand vous aurez écrit vos scripts, vous les aurez sans doute déjà testés (n’est-ce pas ?) sur l’environnement de développement, mais ce qui vous importe vraiment c’est de garantir que ces scripts s’exécuteront sans erreur en production. C’est l’unique objectif de la CI que j’ai configurée. Il peut y en avoir d’autres, comme par exemple déployer les modifications du schéma sur l’environnement de test/recette ou valider la compatibilité de l’ensemble des composants de la plate-forme. Libre à vous de la personnaliser.
Il est important de tester les scripts sur une copie complète de la base de production (schéma et données) pour les raisons suivantes :
Les scripts peuvent contenir des requêtes de migration/transformation de données.
Certaines modifications d’une table peuvent être acceptées ou rejetées en fonction des données qu’elle contient (modification de type de colonne, contraintes d’unicité, etc.).
L’énorme avantage de Snowflake par rapport aux autres solutions est que la copie complète d’une base de données est instantanée et ne coûte rien grâce à la fonctionnalité zero-copy clone. Seuls les deltas des données modifiées généreront un coût de stockage supplémentaire (uniquement si vos scripts modifient les données) sur une durée très courte (le temps d'exécution des pipelines CI). Vous avez donc la possibilité de réaliser le dry run de vos scripts de migration à un prix dérisoire et en un temps record.
L’objectif de mon CD est de déployer automatiquement les modifications du schéma en production. Bien évidemment, vous pouvez le compléter par le déploiement des autres composants de votre plateforme (Ingestion et DataViz).
Voici donc mes besoins exprimés sous forme de User Story :
En tant que Dev paresseux, je veux que mes scripts (deploy & revert) soient validés automatiquement sur un environnement identique à la production dès que je push un nouveau commit sur une branche de merge request et je veux être notifié en cas d’erreur.
En tant que “pas Ops du tout”, je veux que les modifications du schéma soient appliquées automatiquement en production dès qu’une merge request est validée et mergée sur le master.
Ma recette pas-à-pas
Snowflake
Tout d’abord, créez un Warehouse configuré pour être le plus économique possible sur votre compte Snowflake nommé SQITCH (c’est le Warehouse que Sqitch utilise par défaut) :
Ensuite, créez un utilisateur dédié à la CI/CD (je l’ai appelé SQITCH également) :
CREATE USER SQITCH
PASSWORD = <pwd>
MUST_CHANGE_PASSWORD = FALSE;
Cet utilisateur aura besoin des rôles SYSADMIN et SECURITYADMIN :
GRANT ROLE SYSADMIN TO USER SQITCH;
GRANT ROLE SECURITYADMIN TO USER SQITCH;
Gitlab
Afin d’exécuter les commandes Sqitch par le service CI/CD de Gitlab, il vous faudra une image Docker qui embarque l’outil avec toutes ses dépendances correctement configurées.
Pour ne pas réinventer la roue, j’ai pris le Dockerfile de ce projet qui fournit un wrapper des commandes Sqitch permettant de les exécuter via un container (sans installer Sqitch et ses dépendances). J’ai donc dû le modifier légèrement pour l’adapter à la CI/CD de Gitlab.
Voici le contenu de mon Dockerfile :
FROM debian:stable-slim AS snow-build
WORKDIR /work
# Download the ODBC driver and SnowSQL.
# https://docs.snowflake.net/manuals/user-guide/snowsql-install-config.html#downloading-the-snowsql-installer
# https://docs.snowflake.net/manuals/release-notes/client-change-log-snowsql.html
ADD https://sfc-snowsql-updates.s3.us-west-2.amazonaws.com/bootstrap/1.1/linux_x86_64/snowsql-1.1.81-linux_x86_64.bash snowsql.bash
# https://sfc-repo.snowflakecomputing.com/index.html
ADD https://sfc-repo.snowflakecomputing.com/odbc/linux/2.19.5/snowflake_linux_x8664_odbc-2.19.5.tgz snowflake_linux_x8664_odbc.tgz
COPY conf ./
# Tell SnowSQL where to store its versions and config. Need to keep it inside
# the image so it doesn't try to load the version from $HOME, which will
# typically be mounted to point to the originating host.
ENV WORKSPACE /var/snowsql
# Set locale for Python triggers.
ENV LC_ALL=C.UTF-8 LANG=C.UTF-8
# Install prereqs.
ARG sf_account
RUN apt-get -qq update \
&& apt-get -qq --no-install-recommends install odbcinst \
# Configure ODBC. https://docs.snowflake.net/manuals/user-guide/odbc-linux.html
&& gunzip -f *.tgz && tar xf *.tar \
&& mkdir odbc \
&& mv snowflake_odbc/lib snowflake_odbc/ErrorMessages odbc/ \
&& mv simba.snowflake.ini odbc/lib/ \
&& perl -i -pe "s/SF_ACCOUNT/$sf_account/g" odbc.ini \
&& cat odbc.ini >> /etc/odbc.ini \
&& cat odbcinst.ini >> /etc/odbcinst.ini \
# Unpack and upgrade snowsql, then overwrite its config file.
&& sed -e '1,/^exit$/d' snowsql.bash | tar zxf - \
&& ./snowsql -Uv \
&& echo "[connections]\naccountname = $sf_account\n\n[options]\nnoup = true\nlog_bootstrap_file = ./log_bootstrap\nlog_file = ./log" > /var/snowsql/.snowsql/config
FROM sqitch/sqitch:latest
ENTRYPOINT [""]
# Install runtime dependencies, remove unnecesary files, and create log dir.
USER root
RUN apt-get -qq update \
&& apt-get -qq --no-install-recommends install unixodbc \
&& apt-get clean \
&& rm -rf /var/cache/apt/* /var/lib/apt/lists/* \
&& rm -rf /man /usr/share/man /usr/share/doc \
&& mkdir -p /usr/lib/snowflake/odbc/log \
&& printf '#!/bin/sh\n/var/snowsql --config /var/.snowsql/config "$@"\n' > /bin/snowsql \
&& chmod +x /bin/snowsql
# Install SnowSQL plus the ODDB driver and config.
COPY --from=snow-build /work/snowsql /var/
COPY --from=snow-build --chown=sqitch:sqitch /var/snowsql /var/
COPY --from=snow-build /work/odbc /usr/lib/snowflake/odbc/
COPY --from=snow-build /etc/odbc* /etc/
# The .snowsql directory is copied to /var.
USER sqitch
ENV WORKSPACE /var
Container Registry de Gitlab permet de stocker les images Docker spécifiques aux projets. Si votre projet est sur un Gitlab interne de votre société, il est possible que cette fonctionnalité ne soit pas activée. Vous pouvez donc soit demander à l’administrateur de Gitlab de l'activer soit utiliser un autre dépôt d’images. Sur gitlab.com, Container Registry fait partie de l’offre gratuite.
Buildez et uploadez votre image avec les commandes suivantes :
Si le workflow du CD (deploy_sqitch) est très simple et parle de lui-même, celui de la CI (test_sqitch) mérite quelques explications :
Il crée un environnement vierge dont le nom est suffixé par le numéro de la tâche afin d’éviter tout risque de collision avec un autre environnement.
Il exécute les scripts Sqitch uniquement jusqu’à l’état actuel de la production afin de créer l’ensemble des objets globaux (Warehouses et Roles) qui ne peuvent pas être copiés depuis l’environnement de production.
Il remplace la base créée par une copie de la base de production.
Il exécute les scripts Sqitch afin d’appliquer les nouvelles modifications.
Il détruit l’ensemble de l’environnement en exécutant les scripts revert (voilà pourquoi il est important de les implémenter correctement).
Dans cette approche, il est possible que la CI retourne une erreur sans que ce soit la faute du développeur qui a commité les scripts. Cela se produira, par exemple, si l’état de la base de production a été modifié outre que par le CD. Le résultat reste le même : les modifications ne peuvent pas être appliquées à la production et il vaut toujours mieux s’en rendre compte rapidement.
Comme vous pouvez le remarquer, il n’y a ni le login ni le mot de passe de l’utilisateur Snowflake dans le fichier .gitlab-ci.yml. Pour des raisons évidentes, ces informations ne doivent pas se retrouver dans le code source. Il faut donc les configurer via des variables d’environnement que Gitlab stockera encryptées et injectera dans les pipelines CI/CD.
Allez dans Settings → CI/CD → Variables et ajoutez les variables SNOWSQL_USER et SNOWSQL_PWD.
Voici à quoi vont ressembler les logs de votre CI :
…
…
Vous pouvez désormais activer l’option de Merge Approvals dans Gitlab (sur gitlab.com, il faut avoir au moins le niveau Bronze à 4$/mois pour en bénéficier) qui n'autorisera de merger dans le master une merge request que lorsque toutes les pipelines associées sont terminées avec succès.
Allez dans Settings → General → Merge Requests et cochez la case :
Quelques conseils
Si vous n’êtes pas familier avec Sqitch prenez le temps de jouer avec cet outil pour bien comprendre son fonctionnement et ses limites.
Limitez la portée des modifications d’un script à un seul objet pour avoir la meilleure traçabilité des changements et limiter le risque d’erreur dans le script revert.
Implémentez et testez toujours le script revert tant que les changements sont réversibles. Cela permet de revenir à un état stable en cas d’erreur lors de déploiement et de détruire l’ensemble des objets créés par la CI.
Autant que possible, ne faites qu’une seule requête par script afin de limiter le risque de mettre la base dans un état intermédiaire. Snowflake ne permet pas de faire les modifications de schéma de façon transactionnelle.
Créez une convention de nommage pour les scripts Sqitch. Vu que chaque modification du schéma est représentée par un fichier dont le nombre va sans cesse grandir, une convention de nommage vous permettra de mieux les organiser grâce au tri alphabétique. Voici le pattern de nommage que nous avons utilisé : <object>-<name>-<CRUD>(-<date>). Exemples :
schema-sales-create
table-customer-create
table-customer-update-20190101
Faites très attention lorsque vous écrivez les scripts à ne jamais spécifier la base de données en dur dans les requêtes.
Créez toujours les Warehouses avec l’option INITIALLY_SUSPENDED = TRUE pour ne pas gaspiller votre argent (ou l’argent de votre client) à chaque déclenchement de la CI.
Conclusion
Avec cet outillage, vous pouvez valider vos montées de version de base de données en toute sérénité. Et la bonne nouvelle, c’est que cela ne vous coûtera quasiment rien car les ordres DDL ne sont pas facturés par Snowflake et son zero-copy clone ne consomme pas du stockage.
La CI/CD vous permet également de vous concentrer sur la création de la valeur métier en automatisant les tâches répétitives et chronophages.
En partant des configurations que je vous ai présentées, vous pouvez mettre en place votre CI/CD rapidement et l’améliorer ou la compléter par la suite pour mieux correspondre à vos besoins.
Chaque jour, un nombre croissant d’applications prennent le virage du Cloud. En particulier, AWS ( Amazon Web Services) apporte de nombreux services ainsi que des garanties en matière de fiabilité, performance ou encore sécurité. Une question demeure néanmoins en arrière-plan, comment tester de manière efficace l’intégration de ces services de façon simple, rapide et peu onéreuse ? C’est là qu’intervient Localstack, l’outil que je vais présenter dans cet article.
Localstack, accessible à cette URL,est un framework de tests/mocks open-source pour les applications Cloud, à l’origine un projet Atlassian. Il est facile à utiliser et bénéficie d’une grande communauté. Il fournit une partie des fonctionnalités et APIs présents sur l’environnement réel AWS.
Au moment de l’écriture de cet article, pas moins de 24 services sont couverts : Kinesis, DynamoDB, ElasticSearch, S3, Lambda, SQS, API Gateway pour ne citer que les plus utilisés.
Pourquoi utiliser Localstack ?
Il permet de réaliser des tests d’intégration ou d’acceptation.Étant basé sur des appels d’API REST, il peut être utilisé avec n’importe quel langage de programmation.
L’outil s’intègre parfaitement aux pipelines d’intégration continue exécutant les tests sans avoir à redéployer constamment, et permettant de vérifier régulièrement et aisément les comportements attendus. Les principaux avantages sont listés ci-dessous, ceux qui apparaissent comme une évidence, et d’autres, moins manifestes.
Principauxavantages :
Pouvoir travailler hors-ligne
Pouvoir automatiser les tests d'intégration
S’émanciper du logging dans la console AWS: utilisation sans credentials
Créer et Supprimer des ressources à la volée
Faciliter le débogage (Permet de suivre le flow évènementiel facilement : exemple SQS)
Permettre de s’affranchir de la configuration et de la gestion des permissions
Gagner du temps : conséquence directe des points précédents
Économiser de l’argent : pas besoin de payer pour l’utilisation d’AWS étant donné que seuls des services mockés sont utilisés
Utilisation en pratique
Il est possible d’utiliser Localstack directement, en récupérant l’image Docker.Le projet Localstack peut être cloné à l’URL suivante.
Voilà un exemple de ce à quoi peut ressembler un fichier docker-compose.yml :
Un peu de détails sur quelques unes de ces lignes :
image : Ici, permet de récupérer la dernière image localstack du repo (latest)
port : Permet de faire le binding des ports d’entrée 4567 à 4597 sur les ports de sortie 4567 à 4597 au démarrage du conteneur, ports correspondants aux différents services utilisables ; le détail peut se trouver sur le git localstack
environment : Les variables d’environnement utilisées par localstack avec notamment SERVICES pour définir les différents services qui seront utilisés dans notre application (Ici S3 et ES)
Une fois la configuration faite, il suffit de lancer l’application avec la commande :
docker-compose up -d
Pour vérifier que tout s’est lancé correctement, il suffit d’appeler directement le endpoint de localstack, exposé par défaut sur le port 8080, ou d’un service particulier, par exemple ElasticSearch sur le port 4571. Alternativement, lancer la commande “docker ps” permet de s’assurer du bon lancement du conteneur.
Utilisation avec le CLI (Interface en ligne de commande d’Amazon)
Une fois localstack lancé, il est possible d'interagir avec en utilisant le CLI comme on le ferait dans un environnement nominal, en précisant toutefois l’URL du service utilisé, par exemple, pour afficher les buckets présents dans s3, la commande devient :
aws --endpoint-url=http://localhost:4572 s3 ls
/!\ Pro Tip : Il existe maintenant awslocal qui permet d’utiliser les commandes du cli en s’affranchissant de la configuration du endpoint localstack, et donc de connaître le port de chaque service.
Un scénario minime d’utilisation de S3 :
//Lister l’ensemble des buckets, pour l’instant aucun n’est présent
aws --endpoint-url=http://localhost:4572 s3 ls
//Créer un bucket nommé my-test-bucket
aws --endpoint-url=http://localhost:4572 s3 mb s3://my-test-bucket
// Lister l’ensemble des buckets, my-test-bucket est présent
aws --endpoint-url=http://localhost:4572 ls
> my-test-bucket
//Créer un fichier de test
echo "{\"Text\" : \"Ceci est un fichier de test\"}" > test.json
// Uploader le fichier créé dans le bucket
aws --endpoint-url=http://localhost:4572 s3 cp test.json s3://my-test-bucket
//Afficher le contenu du bucket, le fichier est bien présent
aws --endpoint-url=http://localhost:4572 s3 ls s3://my-test-bucket
> test.json
Le fichier, maintenant présent dans un bucket S3, est alors prêt à être utilisé avec n’importe quel service d’AWS, comme on le ferait dans un environnement nominal.
Intégration avec Junit
Afin d’utiliser localstack dans nos classes de test Java, il faut avoir recours au Runner spécifique (LocalstackTestRunner) dans le cas de Junit 4 ou de l’extension (LocalstackExtension) dans le cas de Junit 5, tous deux présents dans la librairie localstack.
Pour ajouter les différents paramètres, il faut employer l’annotation @LocalstackDockerProperties, également dans la librairie localstack.On y précise alors notamment les services qui seront utilisés ainsi que la référence d’image docker.
Ci-dessous, un extrait du pom contenant les artefacts pour Junit 5 et Localstack :
En pratique, dans mon projet actuel, on s’en sert notamment avec le service managé ElasticSearch d’AWS. On l’utilise, par exemple, pour tester l’indexation à partir de fichiers déposés dans S3. Des cas de tests furent alors implémentés pour tester ce simple scénario ; un fichier est créé, puis uploadé dans S3 et enfin indexé dans ElasticSearch.On peut alors ensuite, s’assurer du fonctionnement nominal, avec des tests d’intégration sur le service de requêtage.
Dans un premier temps, est défini une classe Utils avec les méthodes nous permettant d’émuler les services du SDK Amazon, tels que, dans notre cas AmazonS3 et AWSElasticsearch, ainsi que les propriétés localstack.
import cloud.localstack.TestUtils;
import cloud.localstack.docker.LocalstackDocker;
public class LocalStackUtils {
public static final String LOCALSTACK_VERSION = "0.10.2";
public static final String REGION = "eu-central-1";
public static final String BUCKET_NAME = "my-test-bucket";
public static AmazonS3 createS3Client(String region) {
String endpointS3 = setAwsS3EndpointUrlProperty();
AWSCredentialsProvider credentialsProvider = TestUtils.getCredentialsProvider();
return AmazonS3ClientBuilder.standard()
.withEndpointConfiguration(
new AwsClientBuilder.EndpointConfiguration(endpointS3, region))
.withPathStyleAccessEnabled(true)
.withCredentials(credentialsProvider)
.build();
}
public static String setAwsS3EndpointUrlProperty() {
String endpointS3 = LocalstackDocker.INSTANCE.getEndpointS3();
System.setProperty("aws.s3.endpointUrl", endpointS3);
return endpointS3;
}
// ...
// De la même façon on crée une méthode pour la création du client ES ainsi que le set du endpoint
...
public static void uploadFileToBucket(AmazonS3 s3Client, String filePath, String pathOnS3, String bucketName) {
try {
File fileToUpload = new ClassPathResource(filePath).getFile();
s3Client.putObject(bucketName, pathOnS3, fileToUpload);
} catch (IOException e) {
log.error(e.getMessage(), e);
}
}
..
}
Voilà à quoi ressemblerait alors, de façon simplifiée, une classe permettant de tester notre service de requêtage dans ElasticSearch :
Ces deux cas simples, montrent donc comment il est possible de simuler les services AWS avant de vérifier la réalisation pratique de cas précis ; soit en utilisant le CLI soit par une intégration JUnit.
Limites
Malgré toutes ses qualités, il faut garder à l’esprit que c’est un outil open-source, non développé par Amazon, destiné exclusivement à en simuler les services, et donc ne suivant pas infailliblement - ou du moins avec un certain retard - les évolutions des services Amazon, voire ne les prenant pas du tout en compte, pouvant ainsi conduire à des bugs non reproductibles, ou, à l’inverse, empêchant de simuler correctement son application.
De plus, la documentation des APIs n’est pas complète et la version gratuite n’offre qu’une portion limitée des services proposés.Il faut donc, autant que possible, recourir aux environnements Cloud pour garantir la pertinence de ses tests d’intégration en conditions réelles, assurée par l’adéquation des fonctionnalités et comportements entre le développement local et l’environnement Cloud.
Conclusion
Localstack s’avère donc très utile pour émuler facilement et rapidement les services AWS et les intégrer élégamment dans des tests d’intégration, afin de tester des pipelines et comportements applicatifs. Pour moi, il est actuellement une référence parmi les autres solutions existantes et a su démontrer son efficacité et pertinence. Utiliser localstack, c’est à la fois gagner en temps et en qualité dans son développement C’est pourquoi, sur mon projet actuel, il est utilisé profusément à la fois pour vérifier rapidement la faisabilité d’une solution et mettre en place des tests d’intégration efficaces, ce qui était difficilement réalisable avant.
Il faut toutefois garder à l’esprit qu’il reste un outil auxiliaire permettant d’ajouter une lame de plus à son couteau-suisse de qualité logicielle et doit donc être nécessairement utilisé comme tel, comme un framework de test, efficace pour évaluer rapidement le fonctionnement de son code, grâce à des scénarios adéquats.
Comme n’importe quel outil, il est optimal et judicieux, lorsque utilisé dans des cas appropriés.
La toute nouvelle certification de développeur Spark de Databricks (CRT020: Databricks Certified Associate Developer for Apache Spark 2.4 with Scala 2.11 – Assessment) est disponible depuis le 1er août 2019. Ayant obtenu cette certification récemment, je vous partage maintenant mon retour d’expérience. Je vous donne également quelques conseils pour préparer l’examen au cas où vous envisageriez de le passer. J'espère que ce feedback vous permettra de le réussir en toute sérénité.
J’ai passé la certification Spark avec Scala, celle avec Python est sans doute très similaire.
Contenu de l’examen
L’examen est composé de 38 épreuves sélectionnées aléatoirement : 19 questions à choix unique (QCU) et 19 coding challenges. Comme l’indique la notice de l’examen, les épreuves sont pondérées par leur niveau de difficulté dans le calcul du score total. La formule et les coefficients de pondération ne sont pas révélés.
Pour réussir l’examen, il est nécessaire d’obtenir un score supérieur à 70%.
QCU
Les questions ont pour objectif de valider votre niveau de compréhension du fonctionnement de Spark et votre maîtrise de sa terminologie.
Pour chaque question, vous avez à choisir une des quatre réponses proposées. Les questions ne sont pas triées par niveau de difficulté. Il n’y a pas d’obligation d’y répondre dans l’ordre non plus. Vous pouvez à tout moment revenir à une question que vous avez déjà traitée et soumettre une autre réponse.
La plupart des questions de mon examen peuvent être regroupées dans les trois catégories suivantes :
Trouver un intrus parmi 4 affirmations sur le fonctionnement de Spark,
Identifier le bon terme par sa description,
Parmi 4 configurations du cluster (même cluster physique divisé en 1, 2, 4 ou 8 executors) identifier la plus favorable à produire un certain effet.
Il est préférable de ne pas trop s’attarder sur les QCUs, je vous conseille de ne pas passer plus de 30 minutes dessus pour vous laisser plus de temps pour les coding challenges, qui sont beaucoup plus chronophages.
Coding challenges
Les épreuves de coding ont pour objectif de valider votre niveau de maitrise de l’API DataFrame et des différents readers et writers. Aucune épreuve de mon examen n’a exigé l’utilisation de RDD ni de Dataset. Il n’y avait pas non plus de coding challenges sur Spark ML ni sur le Structured Streaming.
Toutes les épreuves de mon examen ont pu être résolues avec très peu de code en utilisant les outils les plus adaptés. Si vous envisagez d’écrire beaucoup de code ou d’utiliser les fonctionnalités avancées de Scala, vous n’êtes probablement pas sur la bonne piste.
Tout comme les QCUs, les coding challenges ne sont pas triés par niveau de difficulté. J’ai eu le plus facile en dernier. Il n’est donc pas judicieux de rester bloqué sur une épreuve qui vous semble compliquée. Vous pouvez passer à la suivante et revenir à celle mise de côté plus tard.
Les épreuves sont à réaliser sur le Notebook de Databricks. Le Notebook n’a pas d'auto-complétion ni de suggestions d’import. Afin de pouvoir exécuter votre code, il faut attacher le cluster au Notebook et lancer le script d’initialisation de l'environnement. Ces opérations sont à répéter pour chaque épreuve.
Chaque coding challenge consiste en l’implémentation d’une méthode dont la signature est fournie. Les méthodes permettant de visualiser les résultats sont déjà implémentées, ce qui vous donne la possibilité d’afficher vos résultats intermédiaires. Vous n’avez donc qu’à remplir la méthode jusqu’à ce que les résultats retournés correspondent aux résultats attendus.
Certaines épreuves sont composées de plusieurs tâches avec plusieurs résultats à retourner par la méthode dans un tuple.
Une fois que vous avez obtenu les résultats souhaités, vous pouvez les vérifier en lançant le script de validation (plus bas dans le Notebook). Vous pouvez lancer le script de validation autant de fois que vous voulez.
Le tutoriel indique que le code qui ne compile pas ne vous apporte aucun point.
Pré-requis
Databricks fait appel à la plateforme ProctorU pour planifier et encadrer les sessions d’examens individuels en ligne. Vous pouvez trouver l’ensemble des pré-requis de la plateforme ici.
Les examinateurs de ProctorU étant aux États-Unis, le créneau disponible est ainsi entre 14h et 2h (5:00 AM - 05:00 PM Pacific Time), tous les jours, y compris les weekends.
Vous avez besoin d’une connexion Internet stable avec une bonne bande passante afin de transmettre la vidéo de votre Webcam et de votre écran sans interruption à l'examinateur. Vous pouvez tester votre environnement en suivant ce lien.
Déroulement de l'examen
Tout d’abord, il est nécessaire de se prendre en photo avec la Webcam, photographier sa pièce d’identité, saisir un texte, télécharger et lancer une application de ProctorU. Cette application qui vous permettra de prendre contact avec votre examinateur par chat et appel vidéo, ainsi que partager votre écran et lui donner la main sur votre poste. Soyez prêt à communiquer en anglais avec un américain.
L'examinateur vous demandera de poser votre téléphone à un endroit derrière vous, visible dans la caméra. Il vous demandera également de lui montrer l’ensemble de la pièce où vous vous trouvez, pour s’assurer que vous y êtes seul et que vous ne disposez d’aucunes sources d’information ni de communication.
L'examinateur prendra la main sur votre poste afin de vérifier que vous n’avez aucune application ouverte, désactivera les screenshots et démarrera votre session. Il ouvrira une fenêtre de navigation privée avec 4 onglets : 3 sites de documentation autorisés et 1 onglet avec l’examen.
L’examen est prévu pour une durée de 3 heures environ. Il n’y a pas d’obligation de respecter ce timing à la minute près. Vous pouvez donc potentiellement le dépasser si vous en avez besoin. En comptant en plus le temps nécessaire pour démarrer la session en toute conformité, il faut prévoir un créneau de 4 heures. Vous n’avez pas le droit de vous absenter durant tout l'examen.
Pendant l'examen vous avez le droit de vous servir de trois sites de documentation : Apache Spark, la documentation Databricks et un site de documentation Scala dont je n’ai pas retenu l’URL. La documentation de Scala n’est pas de grande utilité pendant l’examen car les épreuves ne nécessitent que les connaissances les plus basiques de ce langage. En revanche, en absence de l’assistance de mon IDE préféré, je me suis beaucoup servi de la documentation de l’API Scala de Spark.
Comment se préparer ?
A mon avis, la meilleure façon d'appréhender Spark est de lire attentivement le livre “Spark: The Definitive Guide” de O’Reilly, tout en mettant en pratique les exemples de code disponibles sur Github avec des échantillons de données. Pour cette certification en particulier, il suffit de bien assimiler les parties I, II et IV de ce livre.
Le livre n’est pas exhaustif sur les fonctions de transformation disponibles dans Spark pour deux raisons :
elles sont très nombreuses,
le livre était écrit à l’époque de Spark 2.2, de nouvelles fonctions ont été ajoutées dans les versions 2.3 et 2.4.
Je vous conseille donc de compléter les exercices du livre par des exercices que vous pouvez inventer vous-même sur chaque fonction disponible dans org.apache.spark.sql.functions. Je trouve qu’inventer des exercices est un moyen particulièrement efficace pour bien comprendre et mémoriser chaque fonction et le besoin auquel elle répond.
Prenez le temps de jouer avec les readers et writers du Spark Core (JSON, CSV, Parquet, ORC, JDBC, Avro). Mettez en pratique l’utilisation de leurs options.
Afin de vous mettre en condition d’examen, faites les exercices sans assistance d’un IDE en n’utilisant que les sites de documentation autorisés.
Vous pouvez exécuter le code en mode local (sans cluster) avec spark-shell ou en configurant un projet Maven ou sbt avec Spark. Il est également possible d’utiliser la version gratuite de la plateforme Databricks (je n’ai jamais réussi à obtenir l’accès).
Conclusion
Maintenant que j’ai démystifié la nouvelle certification de Databricks, vous savez désormais à quoi vous attendre et comment vous y préparer. À vous de décider si vous en avez besoin et planifier votre session !
Annoncée à la Google I/O 2019, CameraX fut présentée comme étant l’API permettant d’améliorer et de simplifier considérablement le développement photo dans le monde Android.
Cette librairie est, à l'heure où j'écris cet article, en alpha, mais elle présente déjà un certain nombre de nouveautés assez puissantes sur lesquelles nous allons nous intéresser ici.
Suite au Meetup Android (organisé par le GDG Android Nantes) que j’ai co-animé avec Thomas BOUTIN le mardi 10 septembre 2019 dans nos nouveaux locaux nantais, et dans lequel je présente CameraX, j’ai décidé d’en faire un article afin de vous en parler de façon plus approfondie.
Petit état des lieux de l’avant CameraX
Si vous vous êtes déjà frottés au développement photo dans une application Android, que ce soit avec Camera2 ou même Camera1, vous avez déjà dû constater que ce n’est pas une mince affaire.
Camera2 est une API relativement puissante mais qui nécessite une connaissance assez pointue et donc une prise en main assez longue et fastidieuse. Le code au final est lourd et difficilement maintenable. Jugez par vous-même avec ce petit tutoriel disponible sur Internet.
Vous remarquerez que nous devons utiliser différents objets tels que CameraManager, CameraDevice, CaptureRequest, CameraCaptureSession, etc., et j’en passe.
D’autre part, vous devrez gérer vous-même le cycle de vie de Camera2 : ce sera à vous de définir quand éteindre la caméra, quand la démarrer et quand notamment gérer le cas de la rotation d’écran (un cas qui peut facilement faire planter votre application si vous n’y faites pas attention). Pour cela, vous devrez surcharger les fonctions de cycle de vie de l’Activity ou du Fragment que vous utiliserez, par exemple onStart(), onResume(), onDestroy(), etc.
Ensuite, vous devrez faire en sorte que votre code fonctionne avec la multitude de terminaux Android présents sur le marché, ce qui représente 80% des devices sur le marché, sans compter les différentes versions Android présentes (au contraire d’Apple qui maîtrise ses devices de A à Z). Autant de choses que vous devrez prendre en compte pour avoir une application photo la plus fiable et la plus robuste possible, il n’y a plus qu’à vous souhaiter bon courage ! :D
Enfin, on notera également que les téléphones de façon générale ont connu une évolution importante dans le domaine de la photo depuis plusieurs années : on est passé de 1 à 2, 3 voire même 5 objectifs à l’arrière (cf. le Nokia 9 PureView), et d’autre part, de nouveaux modes “logiciels” plus orientés professionnels sont venus s’ajouter au monde Android, notamment le mode HDR, le mode nuit ou encore le mode portrait. Tout cela améliorant considérablement la qualité de nos prises de vues.
Tout ça pour simplement récupérer un flux photo et faire une capture, alors pour des fonctionnalités plus poussées telles que de la reconnaissance d’image par exemple, je vous laisse imaginer.
Vous l’aurez convenu, difficile donc de réaliser une application orientée photo et avec des fonctionnalités un minimum poussées avec du code propre, simple et facilement compréhensible.
Et Google présenta CameraX...
Rapide introduction
Si vous avez suivi de près la Google I/O de mai 2019, vous aurez repéré qu’une présentation de 30 minutes est consacrée à CameraX.
Cette librairie est présentée comme ajoutant une couche d’abstraction à Camera2. En effet, CameraX apporte une nouvelle façon de développer une application photo en reprenant l’ensemble des fonctionnalités de Camera2, mais l’énorme avantage est que toute la partie hardware est complètement transparente pour le développeur. Fini les problèmes de compatibilité ou les gestions selon les constructeurs :
if (Build.MANUFACTURER.equalsIgnoreCase("samsung")) {
... // This code will make you die a little inside.
}
Pour l’instant, l’API est en version alpha, cela signifie que Google est en pleine phase de prise de feedbacks de la part des développeurs qui auront pu jouer avec la librairie.
Enfin, CameraX fait partie du programme Android Jetpack dont nous allons faire un petit rappel dans la partie suivante.
Android Jetpack
Android Jetpack est un programme lancé lors de la Google I/O 2018. Avant ce programme, chaque développeur Android était plus ou moins livré à lui-même car il n’y avait pas de bonnes pratiques de définies par Google. Chacun appliquait donc ses propres recommandations quant à l’architecture à utiliser notamment.
Google a voulu répondre à cette problématique en sortant Android Jetpack. Il s’agit d’un programme qui comprend un ensemble de librairies et d’outils visant à aider les développeurs à écrire des apps Android de meilleure qualité, avec une architecture cohérente, maintenue et performante, et avec du code plus fiable et permettant de simplifier les tâches complexes.
Jetpack comprend notamment les Android extension libraries (autrement appelées AndroidX), des librairies visant à gérer les problèmes de rétrocompatibilité longuement présents dans le monde Android. CameraX vient s’inscrire dans ce programme, plus précisément dans la partie Behavior, une partie composée de librairies permettant d’intégrer les différents services Android (notifications, permissions, médias, etc.).
Le schéma de Jetpack est articulé de la façon suivante (remis à jour avec les derniers composants) :
La catégorie qui va nous intéresser ici est Architecture. Cette catégorie regroupe des librairies dont le but est de développer des applications robustes, facilement testables et facilement maintenables. Ces librairies permettent notamment de gérer le cycle de vie des composants ainsi que la persistance des données. Entre autre, les composants tels que les Activity ou les Fragments seront “conscients” du cycle de vie qu’ils contiennent (ils sont LifecycleOwner) et pourront ainsi l’exposer. Cela va permettre à d’autres composants qui observent (LifecycleObserver), et qui sont donc lifecycle aware, de pouvoir gérer leurs actions selon les cycles de vie des LifecycleOwner.
Si les Android Architecture Components sont quelque chose de nouveau pour vous, vous pouvez lire cet article de Thomas BOUTIN, qui présente de façon claire les différents avantages des librairies. Si vous souhaitez approfondir vos connaissances, vous pourrez ensuite suivre une mise en pratique composée de 7 articles (en commençant ici) afin de maîtriser les AAC jusqu’au bout des doigts. ;-)
Revenons à CameraX. La raison pour laquelle j’ai pointé la partie Architecture du doigt est relativement simple : dans l’état des lieux de l’avant CameraX, j’énonçais le fait qu’il fallait gérer soi-même l’ouverture et la fermeture de la caméra en se calquant sur le cycle de vie du composant qui l’intègre. Et bien avec CameraX, vous n’aurez plus ce problème ! Et ce grâce à une seule et unique fonction qui gèrera tout à votre place (et qui fera même le café), elle s’appelle bindToLifecycle(). Littéralement, on peut traduire ça par “brancher au cycle de vie”. Cela signifie qu’une fois votre composant CameraX configuré, vous n’aurez plus qu’à le brancher au cycle de vie exposé par votre LifecycleOwner.
Ainsi, vous n’aurez plus à surcharger les méthodes onStart(), onResume(), etc., puisque la fonction gèrera tout cela et ce sera totalement transparent pour vous.
Imaginez donc le nombre de lignes de code en moins rien qu’avec cette fonction. ;-)
Nous verrons comment cela s’implémente concrètement dans la partie technique.
“Mais dis-moi Jamy, comment ça marche CameraX ?”
Nous venons de voir comment CameraX gérait les cycles de vie, nouveauté somme toute, plutôt puissante.
Nous allons voir ici comment cette librairie s’implémente concrètement.
CameraX est une API basée sur des use cases. Le but est de pouvoir nous concentrer sur ce que nous souhaitons que l’application fasse, et d’arrêter de passer du temps à gérer les différences des téléphones niveau hardware.
Voici les use cases basiques, sur ce schéma repris directement de la Google I/O :
En premier, on aura le use case Preview, il s’agira simplement d’afficher le flux vidéo sur notre écran.
Ensuite, on aura Image analysis. Comme son nom l’indique, ce use case va permettre de faire de l’analyse d’image en extrayant des informations sur la luminosité par exemple, ou en les envoyant notamment à des algorithmes. Un cas intéressant est l’utilisation de MLKit qui va nous permettre de faire de la reconnaissance d’image par exemple.
Enfin, Capture va nous permettre de sauvegarder simplement la photo (ou la vidéo).
Dans ces 3 use cases, on va pouvoir définir une configuration plus ou moins commune. On va pouvoir par exemple définir la résolution, le ratio, l’utilisation du flash, l’objectif avant ou arrière, la qualité de l’image, etc. Nous verrons tout cela tout à l’heure dans la démo.
Ainsi, on se détache totalement des problèmes rencontrés dans les versions précédentes de l’API Camera, et vous verrez qu’en quelques dizaines de minutes, vous pourrez développer une application photo un minimum fonctionnelle.
Il est aussi important d’ajouter que Google a prévu les fonctionnalités avancées telles que le mode HDR, le mode nuit, le mode beauté ou encore le mode portrait. Cela est accessible grâce à la librairie appelée Vendor Extensions.
Maintenant, passons à la pratique !
Présentation du projet
Avant toute chose, sachez que je vais pas m’attarder sur ce qui ne concerne pas CameraX. Il existe une multitude de tutoriels vous permettant de débuter une application Android.
Sachez en tout cas que je vais m’appuyer sur un sample que j’ai développé et qui est présent sur mon GitHub à cette adresse : https://github.com/yannickj10/CameraX-Sample. Ce sample reprend les 3 use cases que nous avons vu tout à l’heure.
Pour expliquer rapidement l’architecture du projet, nous avons :
un MainActivity.kt qui lance le premier fragment (PermissionFragment.kt) selon le navigation graph (nav_graph.xml présent dans les resources). Pour en savoir plus sur les Navigation components (composants aussi issus de Jetpack), vous pouvez retrouver plus d’informations sur la documentation Android ;
un PermissionFragment.kt qui s’occupe de demander la permission à l’utilisateur d’utiliser la caméra (nous n’allons pas nous attarder dessus) ;
un ImagePreviewFragment.kt qui s’occupe d’afficher un aperçu de l’image lorsqu’une capture a été réalisée (nous n’allons pas non plus passer de temps dessus) ;
un CameraConfiguration.kt qui regroupe l’ensemble de la configuration utilisée dans nos 3 use cases ;
un CameraFragment.kt qui va nous intéresser car il implémente les 3 use cases. Ce sont essentiellement des morceaux de code de ce fragment que je présenterai et expliquerai ici ;
enfin, le layout fragment_camera.xml (présent dans les resources) qui contient entre autre la TextureView, le composant permettant d’afficher le flux vidéo.
Explication du code et démonstration
Si vous ouvrez le fragmentcamera.xml, vous aurez une ContraintLayout qui englobe la TextureView et un bouton. Le bouton sert simplement à prendre la photo (avec le use case Capture). La TextureView est définie de façon relativement simple :
On va simplement lui définir un ID et faire en sorte qu’il utilise toute la place de son parent, c’est-à-dire le layout, qui lui-même utilise l’écran en entier. On aura donc un flux vidéo en plein écran.
Maintenant, ouvrons le CameraFragment.kt. Comme je l’ai précisé plus haut, les 3 use cases sont regroupés ici, dans les fonctions buildPreviewUseCase(), buildImageCaptureUseCase() et buildImageAnalysisUseCase().
Dans un premier temps, regardons de plus près la fonction setupCamera(). Celle-ci va récupérer les dimensions de l’écran de notre téléphone et les utiliser pour instancier l’objet CameraConfiguration en lui donnant un ratio, une rotation et une résolution. Cet objet sera ensuite utilisé pour les 3 use cases :
Si vous allez dans le CameraConfiguration.kt, ce ne sont rien d’autre que des variables. Cela nous évite simplement d’avoir à redéfinir la configuration à chaque instanciation des use cases.
Ensuite, vous remarquerez l’appel de la fameuse fonction magique bindToLifecycle() qui reçoit en paramètre le this, c’est-à-dire le fragment et les 3 use cases. Tout simplement, on branche le cycle de vie des use cases au cycle de vie du fragment. C’est le seul morceau de code utile à gérer les problèmes de cycle de vie présents dans Camera2 et Camera.
On peut maintenant se concentrer entièrement sur la configuration et l’utilisation des use cases.
Image Preview
La fonction concernant le premier use case est définie ici :
private fun buildPreviewUseCase(): Preview {
val previewConfig = PreviewConfig.Builder()
.setTargetAspectRatio(config.aspectRatio)
.setTargetRotation(config.rotation)
.setTargetResolution(config.resolution)
.setLensFacing(config.lensFacing)
.build()
val preview = Preview(previewConfig)
preview.setOnPreviewOutputUpdateListener { previewOutput ->
val parent = view_finder.parent as ViewGroup
parent.removeView(view_finder)
parent.addView(view_finder, 0)
view_finder.surfaceTexture = previewOutput.surfaceTexture
}
return preview
}
Dans un premier temps, on définit une configuration avec PreviewConfig dans laquelle on définit différentes valeurs récupérées dans notre CameraConfiguration. On pourra aussi définir quel objectif utiliser (avant ou arrière).
Il est important de préciser que si aucune configuration n’est définie, CameraX sera capable de trouver une configuration par défaut selon la taille et le nombre de pixels de votre écran, le nombre de pixels de vos objectifs photo, et de faire un choix optimal.
On instancie ensuite notre Preview.
Ensuite, Preview met à disposition une méthode pour définir un listener. A chaque fois que la preview sera active, elle va fournir un previewOuput. On doit alors mettre à jour notre viewFinder puis attacher la surfaceTexture de la previewOutput à la surfaceView de notre viewFinder. (J'espère que vous suivez toujours :D )
Voilà, notre preview est prête et est branchée au cycle de vie du composant père. Si vous lancez l’appli en commentant les 2 autres use cases, vous verrez ainsi le flux vidéo.
Image Analysis
Ce second use case est utilisé, comme son nom l’indique, pour de l’analyse d’image. Voici la fonction :
private fun buildImageAnalysisUseCase(): ImageAnalysis {
val analysisConfig = ImageAnalysisConfig.Builder()
.setImageReaderMode(config.readerMode)
.setImageQueueDepth(config.queueDepth)
.build()
val analysis = ImageAnalysis(analysisConfig)
analysis.setAnalyzer { image, rotationDegrees ->
val buffer = image.planes[0].buffer
// Extract image data from callback object
val data = buffer.toByteArray()
// Convert the data into an array of pixel values
val pixels = data.map { it.toInt() and 0xFF }
// Compute average luminance for the image
val luma = pixels.average()
Log.d("CameraFragment", "Luminance: $luma")
}
return analysis
}
La configuration est définie sur le même principe que Preview : on a un objet Config auquel on ajoute des attributs. Ici, on va spécifier que l’on souhaite récupérer la dernière image de la file d'attente (composée de 5 images), en éliminant les plus anciennes.
Si on augmente le nombre d’images dans la file d’attente, l’application paraîtra plus fluide mais l’utilisation de la mémoire sera plus importante.
On va ensuite définir un analyzer qui va nous fournir un ImageProxy. Il s’agit d’un objet regroupant l’ensemble des informations de l’image que l’on souhaite analyser. Il contient par exemple la luminance, le contraste, etc. Dans notre exemple, on extrait la luminance que l’on affiche dans les logs de notre IDE. Plus l’image à l’écran sera éclairée, plus la valeur sera élevée.
Un exemple très intéressant que j’ai d’ailleurs présenté lors du Meetup est la reconnaissance d’image : l’idée est tout simplement d’extraire les infos nécessaires et de les envoyer à l’outil ML Kit. Il est ainsi capable, avec une certaine probabilité, de reconnaître les objets de la Preview. J’avais repris l’application développée dans cet article.
Image Capture
Le dernier use case est donc Capture. Il s’agira de créer une capture de notre flux et de l’enregistrer :
private fun buildImageCaptureUseCase(): ImageCapture {
val captureConfig = ImageCaptureConfig.Builder()
.setTargetAspectRatio(config.aspectRatio)
.setTargetRotation(config.rotation)
.setTargetResolution(config.resolution)
.setFlashMode(config.flashMode)
.setCaptureMode(config.captureMode)
.build()
val capture = ImageCapture(captureConfig)
camera_capture_button.setOnClickListener {
val fileName = "myPhoto"
val fileFormat = ".jpg"
val imageFile = createTempFile(fileName, fileFormat)
capture.takePicture(imageFile, object : ImageCapture.OnImageSavedListener {
override fun onImageSaved(file: File) {
val arguments = ImagePreviewFragment.arguments(file.absolutePath)
Navigation.findNavController(requireActivity(), R.id.mainContent)
.navigate(R.id.imagePreviewFragment, arguments)
Toast.makeText(requireContext(), "Image saved", Toast.LENGTH_LONG).show()
}
override fun onError(useCaseError: ImageCapture.UseCaseError, message: String, cause: Throwable?) {
Toast.makeText(requireContext(), "Error: $message", Toast.LENGTH_LONG).show()
Log.e("CameraFragment", "Capture error $useCaseError: $message", cause)
}
})
}
return capture
}
Je ne vais pas repasser sur la configuration puisqu’elle est similaire à celle de la Preview. Une fois notre ImageCapture instancié, on va pouvoir définir un listener sur notre bouton qui s’exécutera à chaque clic. On crée un fichier temporaire, puis on appelle la fonction takePicture() mise à disposition par l’ImageCapture. Elle prend en paramètre notre fichier nouvellement créé. On va pouvoir ensuite surcharger onImageSaved() et onError(). Dans onImageSaved(), on passe le chemin du fichier créé au ImagePreviewFragment puis on affiche un petit Toast. En cas d’erreur, on affiche simplement son origine.
Vous n’avez rien de plus à faire.
Conclusion
Nous venons de voir au travers de cet article et de la démonstration qu’il est totalement possible d’avoir une application un minimum fonctionnelle en quelques lignes de code. Bien évidemment, elle est basique, et il vous faudra donc lire la documentation afin d’en développer une plus étoffée selon vos besoins, notamment si vous voulez ajouter les fonctionnalités avancées avec les Vendor Extensions.
La simplification du code a permis, selon les premiers retours présentés à la Google I/O, de réduire de 70% le code par rapport à Camera2, ce qui est plutôt considérable.
D’autre part, Google est en ce moment dans une phase d’amélioration de cette API, notamment grâce à un laboratoire appelé Automated CameraX test lab dans lequel ils regroupent plusieurs téléphones, de différents constructeurs et sous différentes versions d’Android et sur lesquels ils réalisent différents tests (tests fonctionnels, tests de performance, etc.). Ils ont ainsi pu déjà corriger des problèmes de crashs d’application ou d’orientation du téléphone par exemple.
A cela s’ajoute le fait qu’ils sont en pleine phase de recueillement des feedbacks de la part des développeurs. Ils ont donc une réelle volonté d’amélioration, et c’est plutôt prometteur.
Enfin, à l’heure où j’écris cet article, le support vidéo n’est pas encore disponible, il n’y a pas de documentation à ce sujet, mais on peut déjà trouver avec quelques recherches un objet appelé VideoCapture. La configuration est similaire à l’ImageCapture, et la prise en main ne devrait donc pas poser problème.
Grâce à cette application, Google souhaite donc “redorer” l’image du développement photo sous Android, et effacer les points pénibles que l’on pouvait rencontrer avec les précédentes APIs, à l’image de ce qui était présenté dans Jetpack, et c’est une très bonne chose !
La société Matillion édite un outil de traitement de données permettant de récupérer, préparer et transformer les données en utilisant la méthode ELT : Extract, Load and Transform (vs. ETL classique).
Comme son nom l’indique, l’ELT consiste à charger les données dans un entrepôt de données avant d’y appliquer les éventuels traitements.
Cette méthode est une alternative de l’ETL. Cette dernière extrait les données depuis la source vers une machine de traitement (Spark, Hadoop etc…) puis une fois le traitement effectué déplace une nouvelle fois les données vers les bases de données d’exposition.
Comprenons rapidement les différences entre ces deux méthodes.
ELT vs ETL
Dans ces deux méthodes on commence par l’extraction des données provenant d’une ou plusieurs sources : API, base de données, ERP, fichiers plats...
Ces méthodes se différencient ensuite puisque l’ELT procède directement au chargement des données dans le ou les entrepôts de données.
Les données sont insérées brutes dans des bases de données de l'entrepôt de données. On qualifie généralement ces bases de « base de staging ».
Les données sont dès la première étape dans les bases qui serviront à leur exploitation, ce qui est l’un des avantages par rapport à l’ETL :
On ne “déplace” qu’une seule fois la donnée.
Les traitements seront écrits en SQL puisque les données sont dans des bases.
La puissance de calcul de l'entrepôt de données étant à disposition, pourquoi s’en priver ? C’est donc celui-ci qui exécute les traitements.
On réussit donc à mutualiser les ressources de calculs pour le traitement des données et pour l’exposition/stockage.
C’est un avantage supplémentaire de l’ELT face à l’ETL, qui nécessite le provisionnement d’une machine intermédiaire pour les traitements, puis de charger ensuite les données dans une autre plateforme.
L’ELT applique les traitements sur les bases de staging souvent non typées, puis réécrit les données dans des bases propres, persistantes, où la donnée est prête à être utilisée.
Comme vous l’aurez compris, cette méthode contraint néanmoins à écrire le traitement en SQL, ce qui n’est pas forcément intuitif, répandu, pratique, efficace ...
Et c’est là que Matillion entre en jeu : il permet de se passer du développement de requêtes SQL imbriquées et illisibles et d’optimiser les connexions aux diverses sources.
Utilisation de Matillion
L’utilisation de Matillion est très simple. Depuis l’interface, on choisit des composants qu’on dépose sur l’espace de travail et que l’on relie dans l’ordre d'exécution voulu. Ces composants permettent d’effectuer différentes actions telles que :
Créer des tables ;
Charger des données ;
Gérer les flux de données ;
Transformer les données ;
Écrire les données ;
Etc.
Capture d'écran de l'interface de Matillion sur le projet d'un client.
L’interface est composée de 5 parties :
Arborescences des jobs créés ;
Liste des composants disponibles ;
Espace de travail du job ouvert ;
Caractéristique du composant sélectionné ;
Liste d’exécution des tâches et logs.
En résumé, des actions classiques de manipulation de données.
Jusque-là rien d’extraordinaire, Matillion permet à première vue de faire ce que proposent déjà d’autres outils sur le marché tels que Talend, Dataiku et autres … Mais en ELT !
Regardons ce qu’il se passe réellement derrière tout cela.
Ces actions disponibles dans l’interface sont en fait traduites par l’outil en code SQL et transmises à un entrepôt de données qui sera responsable de l'exécution du code.
Matillion est un générateur de SQL
Si vous souhaitez vous familiariser avec les entrepôts de données du cloud, je vous invite à lire l’article très complet de Christophe Parageaud : « Data Warehouse dans le cloud : Redshift vs Snowflake», qui traite de deux entrepôts de données dans le cloud dont je vais vous parler dans l’article.
Matillion ne peut fonctionner sans entrepôt de données !
C’est un point crucial qui est parfois mal compris : Matillion n’est pas le moteur des traitements et des transformations des données, il est l’orchestrateur.
L’évolution des offres cloud et l’apparition des services d’entrepôts de données managés ont notamment permis l’apparition de l’ELT et de Matillion, qui se sert de la puissance de calcul des solutions d’entrepôt de données du cloud pour traiter les données et les exposer.
Matillion facilite la connexion à ces entrepôts de données et permet de profiter de leurs avantages tels que la puissance de calcul disponible à moindre coût, la tarification sur mesure de ces solutions ou bien le couplage avec les autres services managés dans le cloud.
En résumé, l’outil est intéressant pour les points suivants :
Managé dans le cloud ;
S’appuyant sur des outils eux-même managés dans le cloud ;
Des vitesses et des puissances de calculs modulables et grandissantes ;
Prise en main possible par des équipes “peu techniques” ;
Une installation et une configuration rapides et faciles ;
Présentation très visuelle des projets.
C’est le type d’outil qui facilite la vie des Data Engineers souhaitant utiliser la méthode ELT ou bien des équipes peu techniques sur certains projets.
Caractéristiques de Matillion
Matillion se décline ainsi en trois différentes solutions, chacune faite pour se connecter à un service d’entrepôt de données dans le cloud :
Redshift de Amazon Web Services ;
Big Query de Google Cloud Plateform ;
Snowflake, solution indépendante reposant sur AWS, Azure ou GCP.
Suite de solution Matillion sur les trois principaux provider de cloud
Ces solutions mettent à disposition différentes fonctionnalités propres aux services d'entrepôts de données concernés.
Cela permet à l’utilisateur de pouvoir choisir sa version de Matillion en fonction de son hébergeur cloud et de ses préférences, chacun des entrepôts de données ayant ses avantages et ses défauts.
Par exemple Snowflake gère l’auto extinction des machines après un temps d’inactivité choisi par l’utilisateur depuis l’interface, ce qui permet un gain d’argent considérable contrairement à Redshift qui (pour le moment) ne le permet pas.
On définit dans la console de Snowflake des “warehouses” (entendre par là “clusters”) en choisissant quel type de machine et combien de machines vont effectuer les traitements et on choisit aussi un temps d’inactivité pour l’auto-stop. L’article d’Arnaud Col « Gouvernance Snowflake» décrit entre autre cela.
Les trois solutions de Matillion possèdent exactement la même interface. Les composants d’orchestration et de traitement sont aussi les mêmes, mais peuvent se différencier par les fonctionnalités que chacune des offres d'entrepôts de données propose.
Installation et facturation
Matillion se lance rapidement depuis la marketplace d’Amazon Web Services, Google Cloud Platform ou bien Microsoft Azure.
Le démarrage de l’outil se fait par le lancement d’une instance dans le cloud, dont la taille détermine certaines caractéristiques du produit (fonctionnalités, nombre de connexions simultanés) et bien évidemment la tarification (serveur + prix licence).
Matillion s’installe sur l’instance avec les configurations choisies par l’utilisateur (le guide d’installation oriente néanmoins vers les configurations recommandées par l'éditeur).
Marketplace AWS permettant de lancer le produit Matillion sur une instance EC2
De même, l’utilisateur peut choisir de payer sa licence à l’année ou bien de payer au temps d’allumage de la machine (à l’heure).
Le choix de paiement est souvent réalisé en fonction de la disponibilité nécessaire de Matillion ; si l’on doit effectuer des traitements aléatoires dans le temps et assez souvent dans la journée, il faudra privilégier la licence à l’année. A l’inverse, si les traitements sont effectués à instant précis dans la journée, le paiement à l’heure peut être très économique en mettant en place l’allumage et l’arrêt automatique de Matillion.
Tarif de Matillion détaillé, à l’heure ou à l’année, en fonction de la taille de l’instance sur la Marketplace AWS
La facturation se fait directement depuis la facture du fournisseur cloud (AWS dans l’exemple), ce qui permet d’avoir premièrement un suivi des dépenses, de bénéficier de la prévision des dépenses de la plateforme et en plus de mutualiser les factures avec tous les autres coûts de plateforme.
Organisation des Jobs Matillion
Matillion propose donc d’effectuer plusieurs actions de manipulation de données, scindées en deux catégories : l’Orchestration et la Transformation.
Très simplement, les jobs d’orchestration vont concerner l’extraction, la connexion aux sources, la création des tables, le chargement et aussi l’orchestration des traitements.
Les jobs de transformation concernent, eux, la lecture des données à traiter, la jointure entre différentes tables, les calculs à réaliser et l’écriture des données.
Orchestration
Create Table Component
Ce composant permet la création de table dans l'entrepôt de données avec tous les avantages que celui-ci propose. Cela va des fonctionnalités indispensables comme du schéma de la table, jusqu’à certaines précisions du :
- Table type : Permanent/Temporary/Transient ;
- Clustering Keys ;
- Data Retention Time in Days ;
- Create/Replace: Create / Create if not exists / Replace.
S3 Load Component
Lorsque l'on travaille sur AWS, ce composant permet de charger les données depuis S3 dans une table en question. Il est possible de charger des données sous différents formats de fichiers, différents encodages, des fichiers zippés, sur un ou plusieurs nœuds, en répliquant la donnée ou non. Un composant additionnel permet en plus d’explorer les données dans les fichiers S3, en obtenant un échantillon afin de détecter automatiquement le schéma de la table à créer.
Table Update Component
Matillion propose de faciliter la connexion à de multiples API, ERP, base de données distante, telle que l’API de Facebook.
Le composant indique tous les champs nécessaires à remplir afin de pouvoir requêter correctement l’API Facebook. L’onglet Help du composant indique comment remplir les champs et contient un lien vers la documentation.
SQS Message Component
Ce composant permet d’envoyer un message dans une queue SQS d’AWS. La configuration est facilitée pour envoyer le message le plus facilement possible vers les queues existantes et accessibles du compte AWS. Cela permet de créer une orchestration basée sur les queues pour déclencher les différents services impliqués, ou bien aussi pour récupérer les logs des exécutions.
Transformation
Join Component
On joint au minimum deux flux de données à ce composant. On définit la table principale, les tables secondaires, le type de jointure, les clefs de jointure. Matillion effectue une vérification à chaque modification du composant, impossible donc de faire des erreurs sur le nom des colonnes, sur la manière de joindre et sur le nom des tables.
Calculator Component
Permet la création ou la modification de colonne sur une table. Une multitude de fonctions sont disponibles depuis le composant, avec la doc écrite directement dans l’outil. Ainsi pour calculer le produit de deux colonnes, modifier le type d’un champ, faire un “CASE WHEN”, tout est à portée de main. De même, les checks de validation sont constants afin d’anticiper les erreurs de syntaxe sur les fonctions utilisées.
Aggregate Component
Matillion facilite l'agrégat de lignes en évitant de passer par de grosses requêtes SQL, avec 10 colonnes en clefs et des erreurs de nommage de colonne. Ici on choisit sa table, on choisit parmi la liste des colonnes celles à prendre en compte pour l’agrégat, on choisit les colonnes à conserver et la fonction d’agrégat sur ces colonnes.
Table Update Component
Ce composant permet de faire une mise à jour sur une table. En renseignant un set de colonnes qui sert de clefs, Matillion va chercher dans la table visée si la ligne existe. Si oui, les champs de cette ligne sont mis à jour, si non, la ligne est insérée.
Avantages
Différents outils ressemblent à Matillion dans l’utilisation (anciens tels que Talend, Dataiku ETL, Informatica, MaleSoft) : drag and drop de composants afin de manipuler les données, connexion dans un ordre logique des composants afin d’effectuer les traitements, disponibilité de nombreuses fonctions et de librairies. C’est pourquoi un Data Engineer ou un développeur ETL n’aura pas de mal à prendre l’outil en main et comprendre son utilisation s’il a déjà utilisé un outil similaire.
Pour les novices, je pense qu’ils comprendront rapidement la logique et la méthode d’utilisation de Matillion pour plusieurs raisons.
La solution Matillion est très visuelle et permet une organisation claire des jobs que l’on souhaite créer. Il est facile de présenter ou de léguer son travail.
On a une réelle idée du flux de données dans notre projet, contrairement aux traitements dans les langages classiques de traitement de données, ou bien dans un script exécutant des requêtes SQL les unes à la suite des autres. Les blocs s'enchaînent dans l’ordre défini tel qu’il apparaît à l’écran.
Job Matillion avec ses différents composants
On sait clairement quelles données sont chargées dans quelles tables, quels types de traitements on effectue, étape par étape, et comment on ré injecte les données dans notre entrepôt de données.
De plus, l’outil fait en sorte que le moins de bugs possible se produisent lors des exécutions en effectuant des checks de validation systématiques à chaque modification. Cela facilite le travail et permet de voir si le composant est bien paramétré avant même d’essayer de l’exécuter. Pouvoir corriger ses bugs avant même qu’ils ne se produisent est gain de temps considérable. On comprend mieux l’utilisation des composants et on apprend plus vite.
En dehors de son utilisation, Matillion est facile à installer et à connecter à l'entrepôt de données. Les solutions Redshift et Snowflake, lancées depuis la Marketplace AWS (et donc installées sur une instance AWS EC2) offrent des endpoints aux différents services tel que S3, SQS, SNS, DynamoDB etc... On peut mettre en place une architecture intéressante en couplant ces services facilement.
Matillion enrichit régulièrement sa palette de connecteurs natifs permettant de se connecter plus facilement à une multitude de sources de données différentes telles que des ERP (Salesforce, SAP), des bases de données (ElasticSearch, SDK), des API (Facebook, Twitter, Instagram) et bien d’autres.
Partenariat IPPON
Après trois missions passées à utiliser Matillion dans des contextes différents, je pense l’outil opérationnel pour certains types de projets.
L’interface graphique facilite l’organisation et l’avancée du projet en gardant une vision macro des traitements. Cela permet de plus de faire des présentations interactives aux clients ou aux équipes métiers, en montrant des échantillons de données après chaque étape de traitements, et surtout en leur partageant notre vision élargie du projet, en montrant les différents flux, les jointures nécessaires, les différentes tables utilisées et les outputs.
Il faut garder en tête que les traitements sont effectués par l'entrepôt de données auquel se connecte Matillion et que tout n’est pas réalisable pour autant, certains projets seront plus adaptés à du traitement ETL classique.
Pour l’ELT, Matillion est un gros plus, il permet notamment :
Un gain de temps en développement lorsque les sources de données sont nombreuses ;
Une transmission des connaissances facile ;
Une économie en mutualisant le stockage et le traitement ;
Le bénéfice de la puissance de calculs des solutions d'entrepôt de données disponibles ainsi que leurs avantages.
Les points qui m’ont le plus bloqués sont les suivants :
Communauté restreinte car peu d’utilisateurs ;
Messages d’erreur parfois très vagues ;
Bugs d’interface ;
Frustration liée à la limitation des fonctionnalités de la version de Matillion la moins chère.
Alors que les solutions d'entrepôt de données dans le cloud ne font que s’améliorer, on peut penser que Matillion est un outil à potentiel, tout comme la méthode ELT qui va prendre de plus en plus sens dans les années à venir.
Dans cette suite de 3 articles, je vous présente Vault d’Hashicorp afin de vous donner une vision sur les possibilités qu’offre cet outil pour vos différents projets. La phase d’installation est volontairement omise (le lien vers l’installation de Vault : ici). Cette suite d’article s'appuie sur mon expérience liée à l'utilisation de Vault dans le SI d’Ippon Technologies pour la gestion des secrets dans Ansible et Puppet.
Ce premier article est dédié au fonctionnement de Vault avec un exemple d’utilisation de Vault avec le module Ansible.
Présentation de Vault d’Hashicorp
Général
Vault est une sorte de coffre fort. Celui-ci stocke des secrets sous forme d’arbre. Ceux-ci peuvent être un mot de passe, un token ou un compte MySQL selon le module utilisé.
Hashicorp propose deux versions entreprise. Elles ajoutent des fonctionnalités comme les namespaces et les réplicas en lecture seul.
Sur la copie d’écran suivante, vous pouvez voir que 4 types de secret ont été activés sur ma plateforme de test (pour plus de détails sur les éléments utilisés aws, cubbyhole, KV) :
aws : Permet de générer des access key.
cubbyhole : Stocke des secrets de type clé/valeur. les secrets sont supprimés automatiquement après un délai paramétrable.
kv et secret : Stocke des secrets de type clé/valeur (KV). La différence de ces 2 racines concerne la version du moteur KV utilisé.
Vous remarquerez qu’à chaque module correspond une branche particulière.
Dans la branche “kv”, des sections apparaissent :
Celles-ci peuvent contenir des sous-sections ou des secrets. Dans la section “client2”, deux données apparaissent : “password” et “user”. Un détail lié au module utilisé, KV v2 supporte le versionning des mots de passe..
Les secrets de Vault sont aussi accessible en ligne de commande, par exemple voici la commande pour récupérer un secret
En ligne de commande, pour obtenir le secret client2 :
Dans un premier temps, je définie l’url du serveur et je m’identifie
#On indique l’IP du serveur vault
[root@vault ~]# export VAULT_ADDR=http://192.168.43.241:8200
#Identification via un token
[root@vault ~]# vault login
Token (will be hidden):
Success! You are now authenticated. The token information displayed below
is already stored in the token helper. You do NOT need to run "vault login"
again. Future Vault requests will automatically use this token.
Key Value
--- -----
token s.44q5rRCXSjFZtr8MuXV8vhsJ
token_accessor axsslxXVxNDDt9wwaM1Ft62p
token_duration ∞
token_renewable false
token_policies ["root"]
identity_policies []
policies ["root"]
Puis je lance la commande vault kv get chemin_du_secret
#Lecture d’un secret du moteur kv v2 (valeur/secret) de Vault
[root@vault ~]# vault kv get kv/Client1
====== Metadata ======
Key Value
--- -----
created_time 2019-03-25T15:40:25.400183483Z
deletion_time n/a
destroyed false
version 2 # La version du mot de passe actuelle
====== Data ======
Key Value
--- -----
password La grande question sur la vie, l'univers et le reste
user ippon
# La modification de “client2”
[root@vault ~]# vault kv put kv/client2 user="un test"
Key Value
--- -----
created_time 2019-06-14T14:24:58.384187271Z
deletion_time n/a
destroyed false
version 3 # Nouvelle version
En utilisant le même moteur, voici l’écran de création d’un secret
de même cette action est disponible en ligne de commande:
# Ecriture d’un secret du moteur kv v2 (valeur/secret) de Vault
[root@vault ~]# vault kv put kv/Client4 passcode=my-long-passcode
Key Value
--- -----
created_time 2019-10-21T12:26:22.381178929Z
deletion_time n/a
destroyed false
version 1
Toutes les commandes de Vault sont accessibles par :
API
Interface WEB (ne dispose pas de toute les fonctionnalités)
Ligne de commande
Lorsque Vault démarre, celui-ci se trouve dans un état dit sealed, l’application n’autorise pas l’accès à ses données. Il faut lui communiquer 3 clés (par défaut) pour le passer dans l’état unsealed. Elles sont générées uniquement lors de l’installation et ne peuvent pas être récupérées par la suite. Cette action peut être accomplie manuellement ou automatiquement via des outils comme AWS KVM (Key Management Service). Voici le lien vers le cas d’usage.
Exemple d’utilisation: Module Ansible
Le but de cet exemple est de cacher des mots de passe utilisés dans Ansible et Puppet.Le playbook Ansible est le suivant (la documentation Ansible du module utilisé ici)
secret: la requête passer au serveur Vault. Dans mon exemple nous avons:
kv/data/Client1:password: Le chemin du secret à récupérer dans Vault
token: Le token pour l’identification auprès de Vault
url: l’URL du serveur vault
Retourne le résultat suivant :
PLAY [all]
********************************************************************
TASK [Gathering Facts]
********************************************************************
ok: [127.0.0.1]
TASK [Test_Ansible]
********************************************************************
ok: [127.0.0.1] => {
"msg": "La grande question sur la vie, l'univers et le reste"
}
PLAY RECAP
********************************************************************
127.0.0.1: ok=2 changed=0 unreachable=0 failed=0
On peut remplacer l'identification par token par un autre si besoin, LDAP par exemple. Le token utilisé peut être limité dans le temps ou en nombre d’utilisations. Voici un exemple.
#Création du token
[root@vault ~]# vault token create -policy=client1 -use-limit=3
Key Value
--- -----
token s.MIUbxJ2ySWZADUH9j3EKETng
token_accessor KJ4OBx42EPxx3MHz2tVgW3WM
token_duration 768h
token_renewable true
token_policies ["client1" "default"]
identity_policies []
policies ["client1" "default"]
# Le token est copié dans le playbook
#Premier appel du playbook
[root@client ansible]# ansible-playbook -i 192.168.69.180, tasks/vault.yml
PLAY [all]
******************************************************************
TASK [Gathering Facts]
******************************************************************
ok: [192.168.69.180]
TASK [Test_Ansible]
******************************************************************
ok: [192.168.69.180] => {
"msg": "La grande question sur la vie, l'univers et le reste"
}
PLAY RECAP
******************************************************************
192.168.69.180 : ok=2 changed=0 unreachable=0 failed=0
#Deuxième appel
[root@client ansible]# ansible-playbook -i 192.168.69.180, tasks/vault.yml
PLAY [all] ******************************************************************
TASK [Gathering Facts]
******************************************************************
ok: [192.168.69.180]
TASK [Test_Ansible]
******************************************************************
fatal: [192.168.69.180]: FAILED! => {"msg": "An unhandled exception occurred while running the lookup plugin 'hashi_vault'. Error was a <class 'ansible.errors.AnsibleError'>, original message: Invalid Hashicorp Vault Token Specified for hashi_vault lookup"}
to retry, use: --limit @/etc/ansible/tasks/vault.retry
PLAY RECAP
*****************************************************************
192.168.69.180: ok=1 changed=0 unreachable=0 failed=1
J’ai mis le -use-limit à 3 car, dans mon exemple, le playbook se connecte 3 fois à Vault lors de chaque exécution. La commande vault token lookup permet d’examiner les paramètres liés au token.