Delta Lake apporte de nombreux avantages aux projets Data basés sur Spark. Il peut considérablement simplifier vos workflows grâce aux opérations UPDATE, DELETE et MERGE. Il permet également de rendre vos pipelines plus robustes grâce aux transactions ACID et au schema enforcement. Néanmoins, si votre plateforme est construite avec les services AWS et que vous souhaitez utiliser Delta Lake (projet open source sous license Apache 2.0, donné à la fondation Linux), vous allez être confrontés à quelques difficultés.
L’objectif de cet article est de vous donner des astuces pour les surmonter et des éléments pour mieux évaluer les compromis à faire lors de l’adoption de cette techno dans l’environnement AWS.
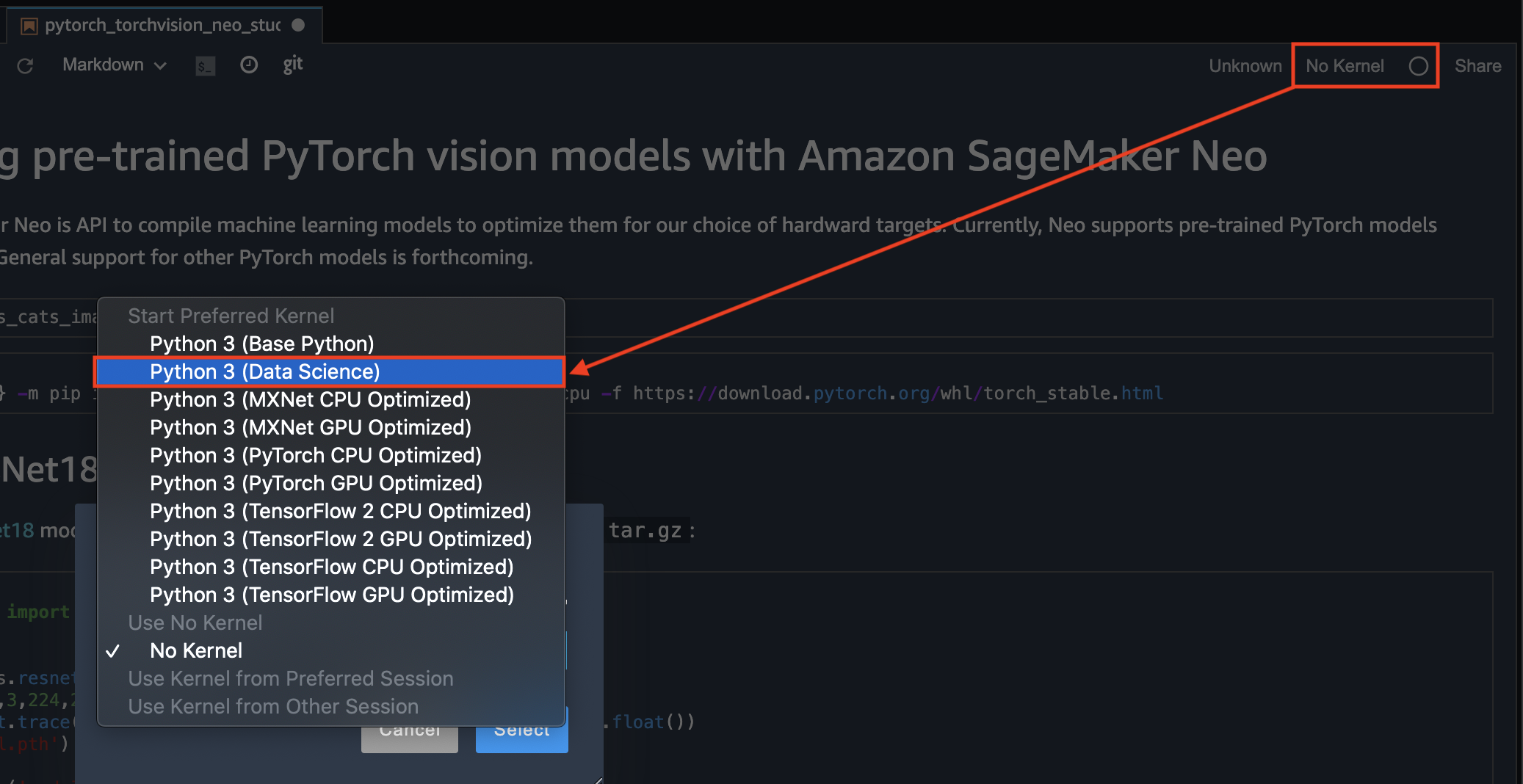
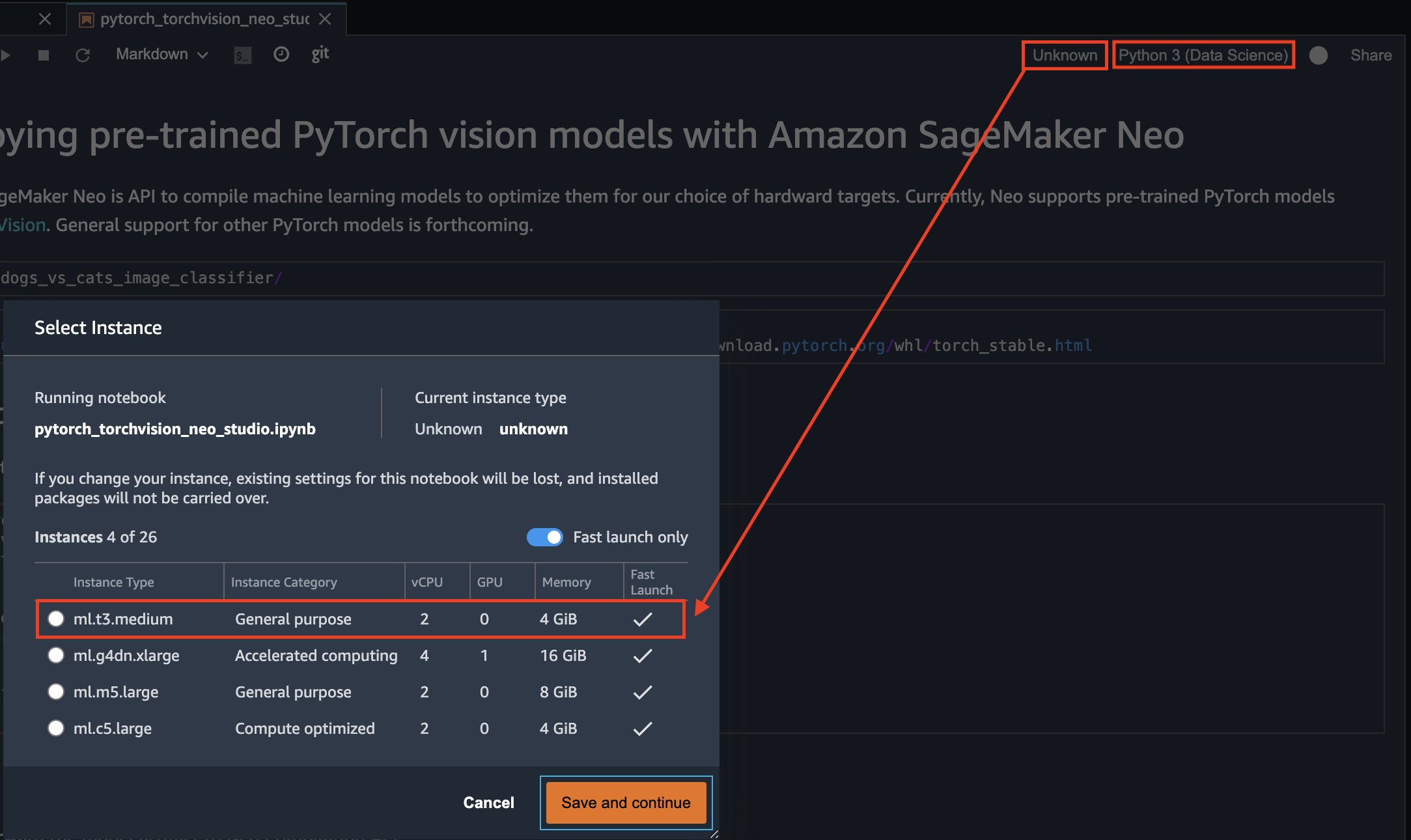
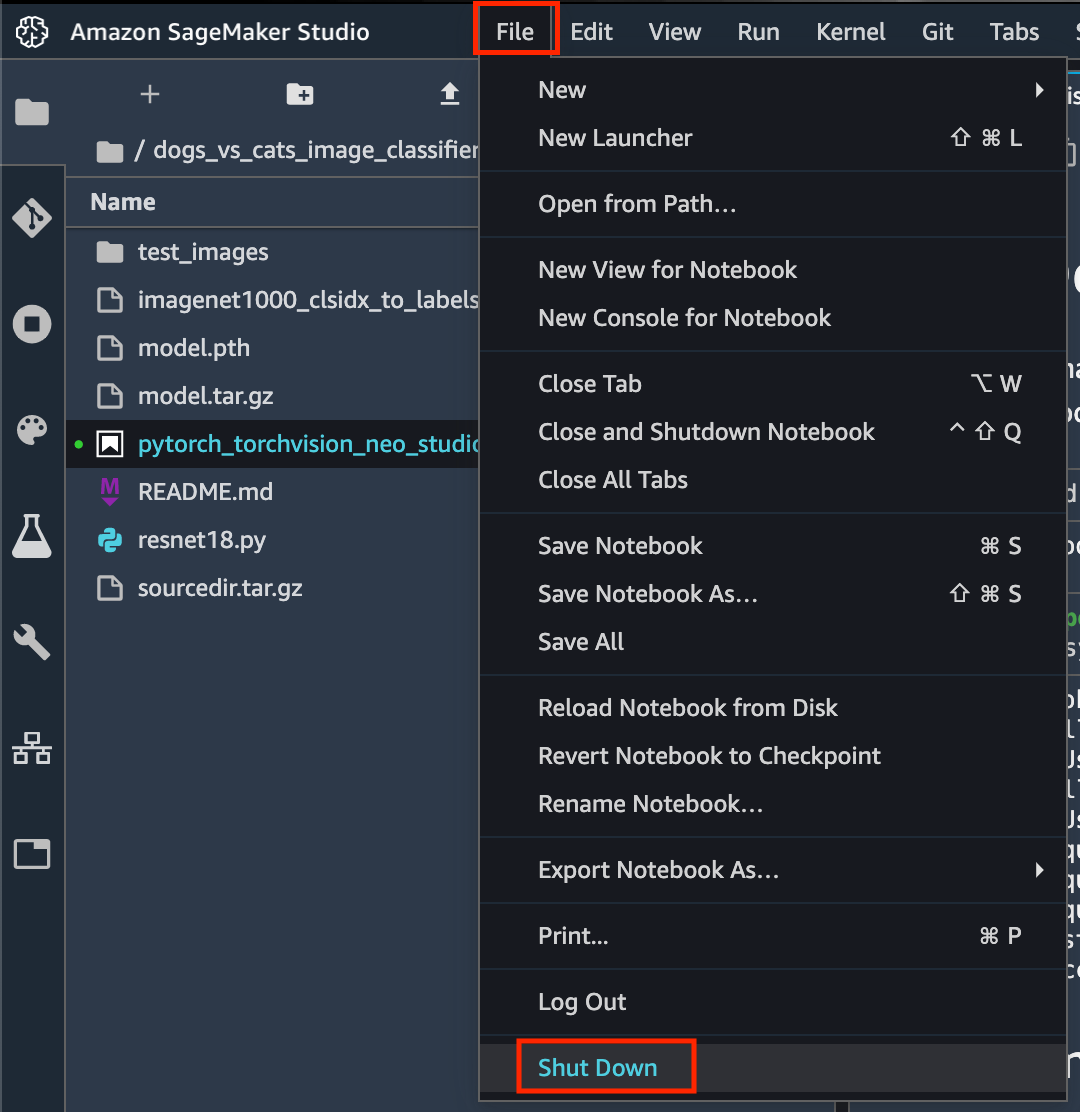
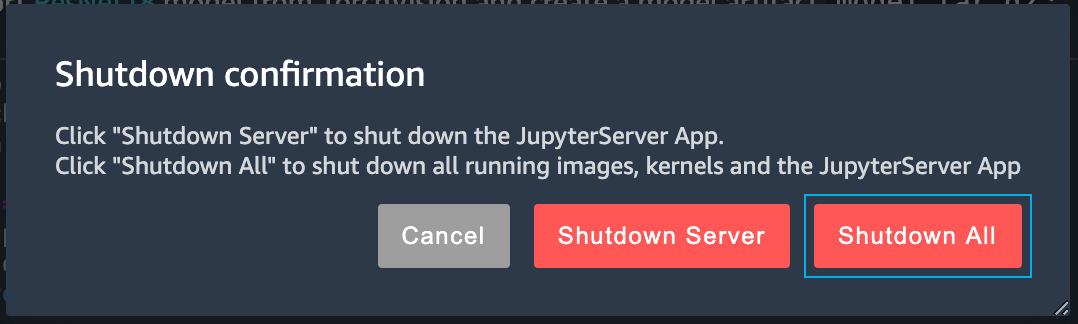
Qu’est-ce que Delta Lake ?
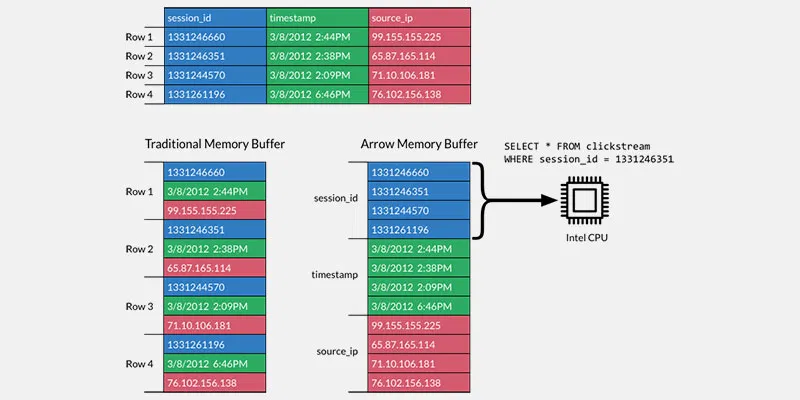
Delta Lake est un format de stockage de données structurées permettant d’y ajouter une couche transactionnelle.
Concrètement, Delta Lake stocke des fichiers Parquets auxquels il ajoute un journal de log. Le moteur peut ensuite utiliser ces informations pour :
- supporter des transactions ACID,
- supporter les opérations UPDATE, DELETE et MERGE,
- assurer un schema enforcement,
- scaler la lecture des metadata même sur des tables très volumineuses,
- supporter à la fois les opérations de streaming et de batch sur les mêmes tables,
- permettre la compaction de fichiers en tâche de fond, pendant qu’un job de streaming tourne, par exemple,
- permettre de consulter l’historique des données (time travel).
Maintenance de table Delta
Delta Lake conserve l’historique des données et permet de consulter leur état à une date ou une transaction donnée. Cette feature est sans coût pour les opérations en append (on ajoute juste de nouveaux fichiers), cependant les opérations UPDATE/DELETE/MERGE vont conserver un historique des valeurs précédentes.
Delta Lake utilise l’approche Copy on Write, aucune opération CRUD sur une table ne supprime les fichiers sous-jacents, elles ne font qu’en rajouter. C’est un fonctionnement assez classique des systèmes transactionnels où tout nouvel état est d'abord persisté en mode append et ensuite commité dans le journal de transactions, les fichiers historiques sont supprimés de manière asynchrone par une opération de maintenance souvent appelée vacuum. Dans le cas de Delta Lake, c’est à vous de programmer l’opération VACUUM en précisant la profondeur de l’historique à garder (7 jours par défaut), sinon vous allez cumuler les fichiers à l’infini. Sachant que la capacité de stockage de S3 n’est limitée que par la taille de votre porte-monnaie, vous risquez de vous en rendre compte bien tardivement.
Le fait de cumuler les fichiers historiques ne dégrade pas les performances des opérations IO sur la table car le moteur ne lit que les fichiers constituant son état actuel. En revanche, le temps d'exécution de l’opération VACUUM dépend directement du nombre de fichiers à supprimer et à garder. J’ai pu constater également que VACUUM prend au minimum 1’30’’ de temps d'exécution sur EMR même pour une table sans aucune historique à supprimer, peu importe la taille du cluster. C’est à vous de trouver la fréquence optimale de cette opération en tenant compte de son coût EMR, du coût de stockage S3 des fichiers historiques et de la fréquence de mises à jour de votre table.
Un autre problème à résoudre est l'accumulation de très nombreux petits fichiers. Cette fois-ci, ce n’est pas directement lié au caractère transactionnel de Delta Lake mais plutôt à la possibilité de faire de multiples ajouts et mises à jour des données dans la table. Le problème devient critique si la table est alimentée en Streaming. Il est donc nécessaire de compacter les fichiers régulièrement. La version propriétaire de Delta Lake disponible exclusivement sur la plateforme Databricks met à votre disposition les outils nécessaires pour le faire. Vous pouvez programmer l’opération OPTIMIZE ou configurer la compaction et/ou optimisation automatique pour votre table. Dans tout autre environnement, c’est à vous d'implémenter la compaction et de la scheduler dans votre workflow.
Compatibilité avec Athena
Il est possible que vous souhaitiez requêter les tables Delta Lake avec Athena afin de bénéficier des avantages d’un service serverless. Athena est tout à fait adapté pour explorer vos données.
Le format Delta Lake, créé spécialement pour Spark, n’est pas encore supporté nativement par Athena. Néanmoins, il existe une solution de contournement qui consiste à générer le fichier manifest et le référencer dans la requête de création de la table Athena.
Cette approche est bien documentée et paraît assez simple, mais elle vient quand même avec son lot de complexités :
- Le fichier manifest doit être regénéré à chaque transaction sur la table Delta Lake afin qu’Athena puisse lire la toute dernière version des données,
- Le schéma des données n’est plus seulement porté par la table Delta Lake, vous avez le cycle de vie de la table Athena à gérer en parallèle afin d’éviter la désynchronisation des schémas.
La première contrainte est résolue dans la version 0.7.0 de Delta Lake qui permet d’activer la génération automatique du fichier manifest. Notez que cette version n’est compatible avec Spark qu’à partir de la version 3.0 qui n’est à son tour disponible que sur la toute dernière release de l’EMR (6.1.0 sortie en Septembre 2020).
Pour pallier la deuxième contrainte, je vous recommande vivement une astuce qui consiste à considérer la table Delta Lake comme l’unique source de vérité et à mettre en place un mécanisme qui recrée la table Athena à partir de son schéma suite à chaque modification de ce dernier. Exemple en Scala :
val deltaTable = DeltaTable.forPath(spark, "s3a://<pathToDeltaTable>")
val athenaQueryDDL = s"""CREATE EXTERNAL TABLE mytable(${deltaTable.toDF.schema.toDDL})
ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
STORED AS INPUTFORMAT 'org.apache.hadoop.hive.ql.io.SymlinkTextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION 's3://<pathToDeltaTable>/_symlink_format_manifest/';"""
Il reste à exécuter la requête avec AthenaClient fourni avec AWS Java SDK. Notez que le protocole s3a est préférable pour Spark alors que pour Athena le chemin doit commencer par “s3://”.
Les choses se compliquent lorsque la table Delta Lake est partitionnée. Outre les éventuels problèmes de cohérence décrits dans la doc, vous devez exécuter la requête MSCK REPAIR TABLE mytable aussi souvent que de nouvelles partitions apparaissent afin qu’Athena puisse les lire. Vous allez probablement devoir l'exécuter suite à chaque transaction sur la table Delta Lake si la fréquence d'apparition de nouvelles partitions est imprévisible. Faites attention aux coûts AWS que cela va générer.
La table Athena doit être à son tour créée comme une table partitionnée. En plus du schéma des colonnes de la table, nous avons besoin de son schéma de partitionnement. L’API Delta Lake permet de récupérer le schéma de partitionnement mais cela n’est documenté nulle part. Les colonnes du schéma de partitionnement ne doivent pas être répétées dans le schéma des colonnes dans la requête Athena, sinon la requête est rejetée avec une erreur de syntaxe. En tenant compte de toutes ces contraintes et dans le souci de rendre la création de la table Athena totalement générique, mon code évolue pour prendre la forme suivante :
val deltaTablePath = "<pathToDeltaTable>"
val tableName = "mytable"
val deltaTable = DeltaTable.forPath(spark, s"s3a://$deltaTablePath")
val deltaLog = DeltaLog.forTable(spark, s"s3a://$deltaTablePath")
val partitionSchema = deltaLog.snapshot.metadata.partitionSchema
val schema = deltaTable.toDF.schema
val columns = if (partitionSchema.isEmpty)
schema.toDDL
else
new StructType(schema.filterNot(partitionSchema.fields.contains(_)).toArray).toDDL
val createAthenaTableQuery = s"""CREATE EXTERNAL TABLE $tableName ($columns)
${if (partitionSchema.isEmpty) "" else s"PARTITIONED BY (${partitionSchema.toDDL})"}
ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
STORED AS INPUTFORMAT 'org.apache.hadoop.hive.ql.io.SymlinkTextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION 's3://$tablePath/_symlink_format_manifest/';"""
Bug EMR
L'opération MERGE qui permet de combiner les instructions INSERT, UPDATE et DELETE dans une seule requête est une des fonctionnalités les plus intéressantes de la librairie Delta Lake. C’est bien cette fonctionnalité qui n’est pas utilisable sur les versions 5.29.0 et 6.0.0 d’EMR à cause d’un bug connu. Le fait que ce bug soit présent sur deux versions majeures d’EMR témoigne du faible intérêt que porte AWS pour Delta Lake, je vous laisse deviner pour quelle raison...
Conclusion
Vaut-il finalement le coup d’utiliser Delta Lake dans l’environnement AWS ? A mon avis, du moment où votre workflow est un peu plus complexe qu’un simple batch en mode append ou overwrite, vous avez tout intérêt à adopter cette techno. Les bénéfices qu’elle apporte couvrent largement les frais de ce mariage forcé. Enfin, pour n’en tirer que des bénéfices il faut s’orienter vers la plateforme Databricks disponible sur AWS.